
At Liip, we've been building and running AI-powered chatbots for organizations through our LiipGPT platform. Over time, we developed evaluation sets, automated scoring with LLM-as-a-Judge, and various ways to measure chatbot quality. Max wrote about this approach in No value without trust. But when it comes to comparing two different configurations, like a new prompt versus the old one, or GPT-4o versus Claude Sonnet, automated metrics only get you so far. Sometimes you need actual humans reading actual answers and telling you which one is better.
The Bias Problem
The problem is bias. If you know that Response A comes from the expensive model and Response B from the cheaper one, you'll unconsciously read them differently. The idea behind our solution is borrowed from classic A/B testing: show two variants to evaluators without telling them which is which, and let the results speak. For RAG chatbots, the question isn't "which model is generally better?" It's "which configuration produces better answers for this specific knowledge base and these specific users?" That requires comparing pre-generated answers, not live model outputs.
Side by Side, Let's Evaluate
So we built Arena mode into the Admin UI. It works like this: you start by running your evaluation set against two different configurations. Maybe you're testing a new system prompt, or switching embedding models, or trying a different retrieval strategy. Each run produces answers for every question in the set. Then you create a comparison, selecting those two runs.
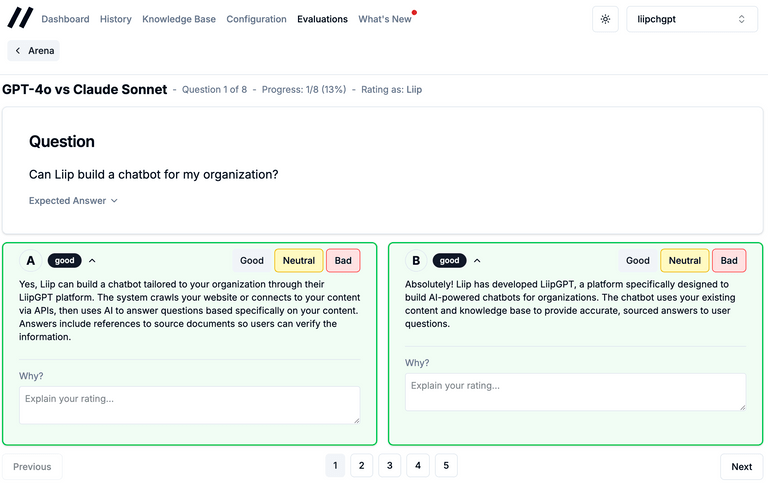
When an evaluator opens the comparison, they see one question at a time. Two answers, labeled A and B. No model names, no hints. The order is shuffled differently for each evaluator using a seeded randomization, so if Alice sees the Claude answer as "A" for question 3, Bob might see it as "B". This prevents evaluators from developing patterns like "A is always the better one."
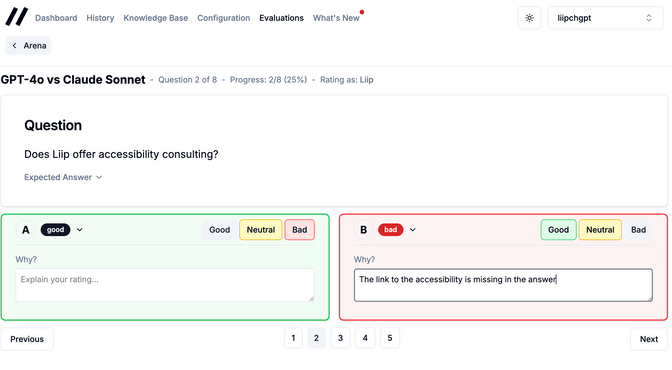
For each answer, you rate it as Good, Neutral, or Bad. You can add a comment explaining why, which turns out to be incredibly valuable. The quantitative scores tell you which model wins, but the comments tell you why, and often reveal issues you wouldn't catch with automated evaluation.
More Feedback the Merrier
Multiple evaluators can rate the same comparison independently. Getting people involved is easy: share links generate a temporary API key, so you can send a URL to a colleague or a client and they can evaluate in a protected area without needing an admin account. They just enter their name and start rating.
Understand the Results
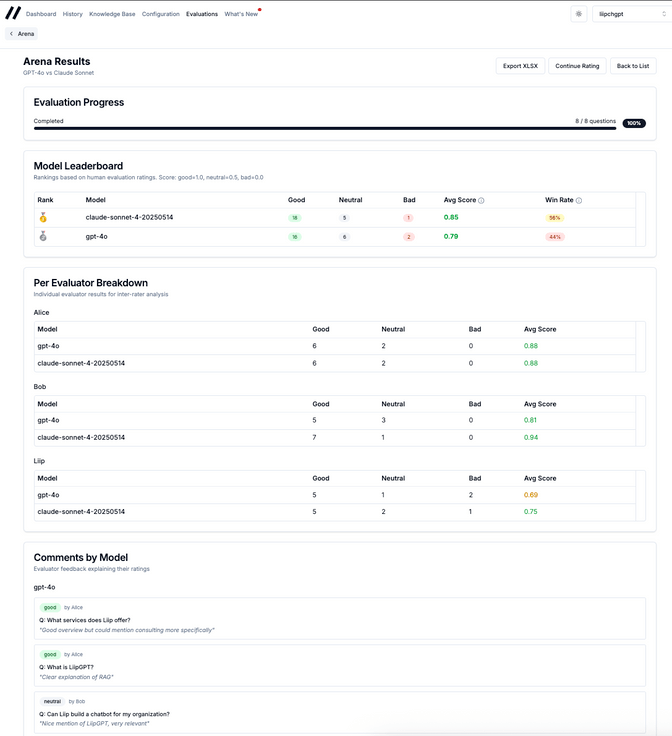
The results page shows a leaderboard: average score, win rate per model, and a breakdown per evaluator. That last part is where it gets interesting: it surfaces inter-annotator agreement, a standard measure of how much evaluators align in their ratings.
- High agreement: the quality difference is clear and you can act on the result with confidence.
- Low agreement: the two configurations are close enough that the choice may come down to other factors like cost or latency.
You can also drill into individual comments grouped by model, and export everything to Excel for reporting.
Calibrating AI with Human Truth
Building this was a good reminder that evaluation tooling is never "done." Christian recently wrote about using Claude Agent SDK to analyze chatbot answers automatically, which is the other side of the coin: scaling evaluation with AI. Arena mode complements that by providing the human ground truth that automated evaluation needs to calibrate against.
We're using Arena now whenever we make significant changes to a chatbot's configuration. The signal-to-noise ratio is much better than staring at spreadsheets of automated scores. The feature is available in the Admin UI for any organization that uses our evaluation sets.
The Next Steps of the Arena
We're considering adding support for more than two models in a single comparison, and possibly integrating the Arena ratings as ground truth labels for training better LLM-as-a-Judge prompts. For now, blind human evaluation with a simple Good/Neutral/Bad rating scheme gives us exactly what we need: honest answers about which configuration actually works better.