

Recommender systems have been a pet peeve of me for a long time, and recently I thought why not use these things to make my life easier at liip. We have a great community within the company, where most of our communication takes place on Slack. To the people born before 1990: Slack is something like irc channels only that you use it for your company and try to replace Email communication with it. (It is a quite debated topic if it is a good idea to replace Email with Slack)
So at liip we have a slack channel for everything, for #machine-learning (for topics related to machine learning), for #zh-staff (where Zürich staff announcments are made), for #lambda (my team slack channel) and so on. Everybody can create a Slack channel, invite people, and discuss interactively there. What I always found a little bit hard was «How do I know which channels to join?», since we have over 700 of those nowadays.
Wouldn't it be cool if I had a tool that tells me, well if you like machine-learning why don't you join our #bi (Business Intelligence) channel? Since Slack does not have this built in, I thought lets build it and show you guys how to integrate the Slack-API, Pandas (a multipurpose data scientist tool), Flask (a tiny python web server) and Heroku (a place to host your apps).
These days there are myriads of ways to build a recommender system and there are lots of commercial and open source solutions out there already. There are recommenders that recommend based on contents of items (e.g. read this book because it is about snakes and planes) or there are solutions that recommend based purely on user behavior data (e.g. people who have bought this book have also bought this book). The latest ones are called collaborative filtering recommenders (fancy name) and we will build one of these since they are easy to build and work reasonably well.
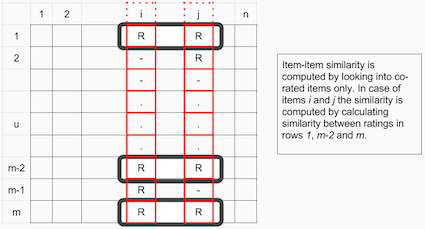
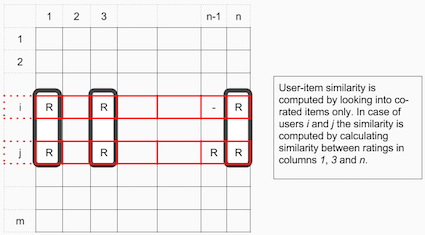
Collaborative Filtering approaches can be divided into two main approaches: user-item filtering and item-item filtering. A user-item filtering will take a particular user, find users that are similar to that user, based on similarity of ratings, and recommend items that those similar users liked. In contrast, item-item filtering will take an item, find users who liked that item and find other items that those users or similar users also liked. It takes items and outputs other items as recommendations.
What does this mean for Slack for us? Well in an item-item approach we might say give me “channels that are similar to machine-learning”. The algorithm will then look who joined this channel and look if there are channels that have been joined by exactly the same people. If that is the case then those channels might be somewhat related. In a user-user approach, we try to recommend a channel to a particular user. So we look through all users and look for the ones that have joined the same channels as our user joined. Then look if there are some channels among those that our user has not joined yet. These ones might be interesting for him.
There are myriads or better blog articles that do a great job explaining in detail on «How to build a recommender in Python» – I think I should at least list a couple of those ( Deconstructing Recommender Systems by Spectrum, Implementing your own recommender in Python by online Cambridge coding, Collaborative Filtering with python by Salem Marafi). There are also a couple of nice Ipython notebooks that you can download and play along ( Playing with recommender systems). If you want to know what the people are doing and who is creating state-of-the-art recommender systems you should visit the Recsys conference. You can also download tons of academic papers on how different recommender systems perform and why some are better than others in different scenarios. There is even a great coursera course on recommenders by Joseph Konstan that I highly recommend. But for the sake of brevity, we can not go into all the details here, we just want to get you started. Right?
What it boils down to is that in our case for Slack you need to construct a matrix of users x channels. If you have a matrix that has users x items, you have a setup that is called “item-item collaborative filtering”, if you rotate this matrix 90 degrees and have a matrix that has items x users you have an user-user collaborative filtering. It is as easy as that. I apologize for stealing those two great images from this great blog post of online Cambridge coding, but they show nicely how things work.
Step 1: Getting the data
So in order to generate the needed data, just create a Slack-client give it some key that you will get from Slack and let it go through all the channels and note down which person is in which channel. Furthermore write down a 1 if a person is in a channel, write down a 0 when not.
Once we have our data we can start working. We will first read in the data into pandas and display it. It is basically two lines of code and you will see the nice matrix unfolding. Notice that we are really working on a tiny dataset here, that's why it is perfectly ok to do everything in memory. But once you have a matrix consisting of millions of row things start to become interesting.

Step2: Computing the distances
In order to know which channels are similar to which other channels, we have to look at those user vectors for each channel, and see if there is another channel for which the same kind of users have also joined. Those channels must have something in common. Now there are myriads of different metrics on «how to compute a similarity between two vectors?», like pearson-correlation, jaccard-distance, manhattan-metric, or cosine similarity. Just pick one. They all have their strengths and weaknesses. For this experiment I went for cosine-similarity. Doing this in Pandas is really easy. Only 4 lines of code and you will have this:
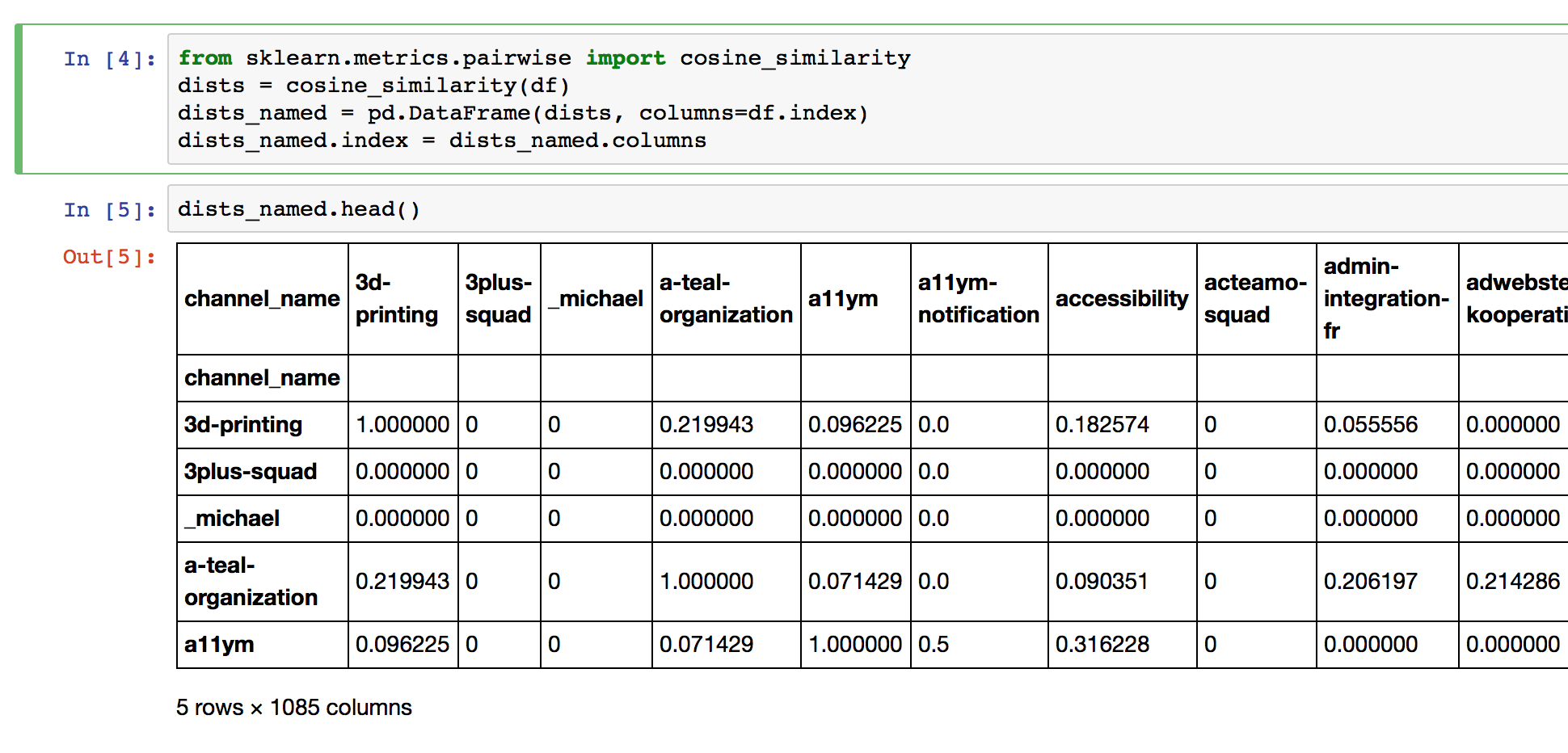
Isn't that great?! We now have a matrix that shows how similar each channel is to the other ones. To make a recommendation we have to look up for a certain channel which other channels have the highest number in that row and we are done.
Step3: Making a recommender
So, to make a recommendation we look for the row matching the channel name and then sort the columns by value and remove one entry. Namely the channel itself, because we know it is similar to itself :). We then output, for example, the 5 highest numbers. Again, this can be done with 4 lines of code in Pandas. You just have to love this thing! See below:
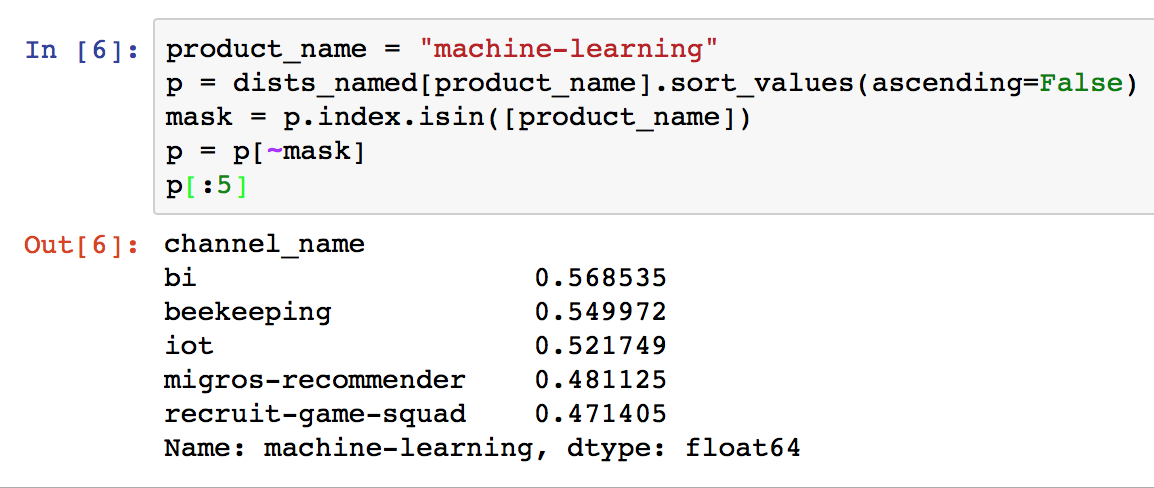
Well, there we have it: apparently if I go to the channel #machine-learning I should also visit #bi and #beekeping. Our company has a weird humor when it comes to naming things. :) I would have never guessed a second, going simply by name. So what is next you ask? Well, it is time to take those results and make them work for the company. At this point we will skip the part where I show you «how to recommend channels for users» or «how to compute users that are similar to each other» or «how to evaluate the results» (In real life, problem evaluations of recommenders is a serious problem and should be definitely part of your approach).
Step4: Build a service out of it
What normally happens it that our precious models and results end up rotting away on our laptop, because we have no time, budget, or priority to turn them into actionable artifacts. But I think this is actually the most important step for a data scientist.
Make sure that your results are understandable and communicate them to people that might find them useful. Make sure you are actually going to act on those results, because that is where you actually helping people. So I thought we must turn this tiny recommender into a website in our company where everybody can get their own recommendations.
That's where F lask helps us. The good thing about Flask is that our recommender code is written in Python and the web server is in Python too, so we can simply cut the code from our notebook and paste it into our web server. This makes our life very easy because normally at this point data scientists struggle because other engineers have to implement their shiny and fancy solution in another programming language. That takes time, lots of swearing from the developers and creates lots of headaches for the data scientist. So my approach uses the same programming language across the whole stack. Then you should be fine. Well, indeed you can create an endpoint in Flask that takes a channel_id and runs your recommender code with it and returns the results as a JSON back to the frontend. You should recognize the same code above in the ipython notebook and here below:
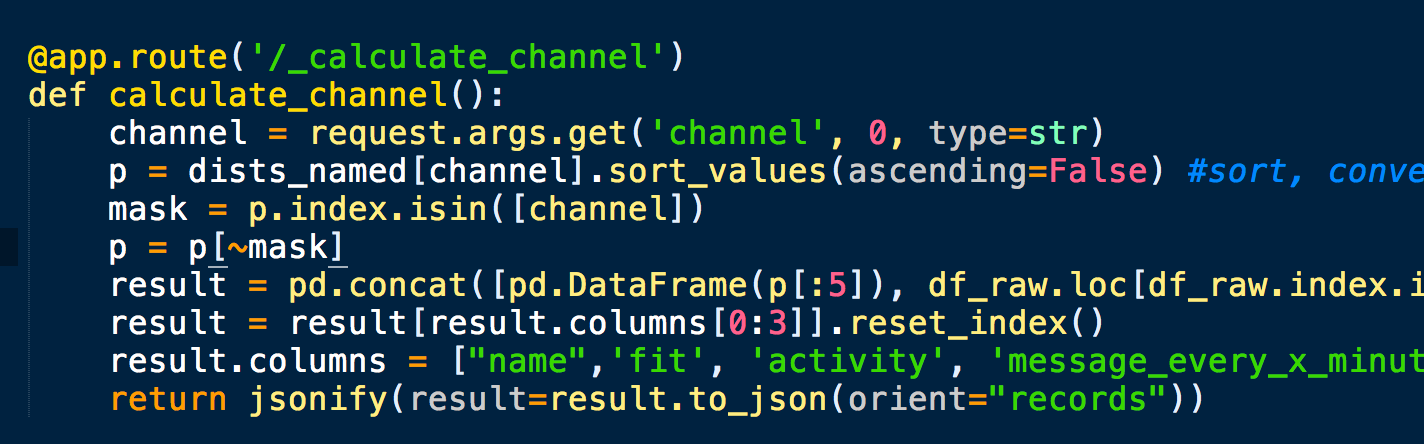
Step 5: Make it look fancy
The last remaining step is to create a nice looking GUI for the recommender where the users can select either a channel or a username. I have also implemented a goofy friend finder, that lists persons that seem to have the similar interests on Slack, based on what channels they use. So given the sea of messages, data and communication it seems to be useful having a tool that can help us out a bit. Now without further ado: I present to you the Liip Slack channel recommender:
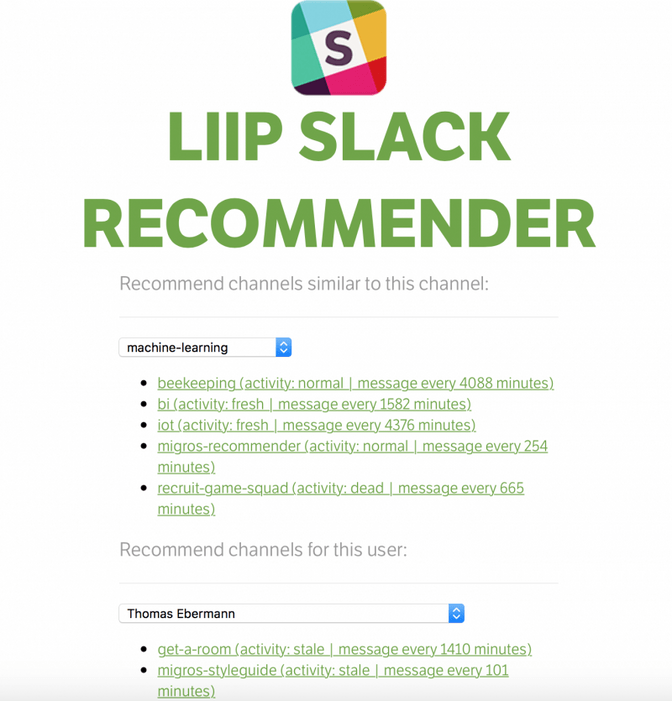
A screenshot of the tool
The only thing left is to push it to Heroku or Cloudfoundry or the provider of your choice. It really makes your life easier if you control the deployment process because this way you can iterate on your model easily without asking your sysops for permission. (Of course, if a big system depends on your algorithm you should get serious about testing, fault tolerance, SLAs and all of that grow up stuff).
If you feel like you have liked the solution drop me a line, and we can send you the code to create this solution for yourself or just talk to us and we will think of something on «how implement recommenders or similar for your slack channels or your people directory». After all, I think these days it is time to not only build good looking, stable, fast and easy to use – but also smart data-driven websites.
If you are a Liiper reading this: click here to login into the recommender. PW/Login are available on #announcements. :)