

Welcome to part three of three in our mini blog post series on how to build a recipe assistant with automatic speech recognition and text to speech to deliver a hands free cooking experience. In the first blog post we gave you a hands on market overview of existing Saas and opensource TTS solutions, in the second post we have put the user in the center by covering the usability aspects of dialog driven apps and how to create a good conversation flow. Finally it's time to get our hands dirty and show you some code.
Prototyping with Socket.IO
Although we envisioned the final app to be a mobile app and run on a phone it was much faster for us to build a small Socket.io web application, that is basically mimicking how an app might work on the mobile. Although socket.io is not the newest tool in the shed, it was great fun to work with it because it was really easy to set up. All you needed is a js library on the HTML side and tell it to connect to the server, which in our case is a simple python flask micro-webserver app.
#socket IO integration in the html webpage
...
<script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/2.1.0/socket.io.js"></script>
</head>
<body>
<script>
$(document).ready(function(){
var socket = io.connect('http://' + document.domain + ':' + location.port);
socket.on('connect', function() {
console.log("Connected recipe");
socket.emit('start');
});
...The code above connects to our flask server and emits the start message, signaling that our audio service can start reading the first step. Depending on different messages we can quickly alter the DOM or do other things in almost real time, which is very handy.
To make it work on the server side in the flask app all you need is a python library that you integrate in your application and you are ready to go:
# socket.io in flask
from flask_socketio import SocketIO, emit
socketio = SocketIO(app)
...
#listen to messages
@socketio.on('start')
def start_thread():
global thread
if not thread.isAlive():
print("Starting Thread")
thread = AudioThread()
thread.start()
...
#emit some messages
socketio.emit('ingredients', {"ingredients": "xyz"})
In the code excerpt above we start a thread that will be responsible for handling our audio processing. It starts when the web server receives the start message from the client, signalling that he is ready to lead a conversation with the user.
Automatic speech recognition and state machines
The main part of the application is simply a while loop in the thread that listens to what the user has to say. Whenever we change the state of our application, it displays the next recipe state and reads it out loudly. We’ve sketched out the flow of the states in the diagram below. This time it is really a simple mainly linear conversation flow, with the only difference, that we sometimes branch off, to remind the user to preheat the oven, or take things out of the oven. This way we can potentially save the user time or at least offer some sort of convenience, that he doesn’t get in a “classic” recipe on paper.

The automatic speech recognion (see below) works with wit.ai in the same manner like I have shown in my recent blog post. Have a look there to read up on the technology behind it and find out how the RecognizeSpeech class works. In a nutshell we are recording 2 seconds of audio locally and then sending it over a REST API to Wit.ai and waiting for it to turn it into text. While this is convenient from a developer’s side - not having to write a lot of code and be able to use a service - the downside is the reduced usability for the user. It introduces roughly 1-2 seconds of lag, that it takes to send the data, process it and receive the results. Ideally I think the ASR should take place on the mobile device itself to introduce as little lag as possible.
#abbreviated main thread
self.states = ["people","ingredients","step1","step2","step3","step4","step5","step6","end"]
while not thread_stop_event.isSet():
socketio.emit("showmic") # show the microphone symbol in the frontend signalling that the app is listening
text = recognize.RecognizeSpeech('myspeech.wav', 2) #the speech recognition is hidden here :)
socketio.emit("hidemic") # hide the mic, signaling that we are processing the request
if self.state == "people":
...
if intro_not_played:
self.play(recipe["about"])
self.play(recipe["persons"])
intro_not_played = False
persons = re.findall(r"\d+", text)
if len(persons) != 0:
self.state = self.states[self.states.index(self.state)+1]
...
if self.state == "ingredients"
...
if intro_not_played:
self.play(recipe["ingredients"])
intro_not_played = False
...
if "weiter" in text:
self.state = self.states[self.states.index(self.state)+1]
elif "zurück" in text:
self.state = self.states[self.states.index(self.state)-1]
elif "wiederholen" in text:
intro_not_played = True #repeat the loop
...
As we see above, depending on the state that we are in, we play the right audio TTS to the user and then progress into the next state. Each step also listens if the user wanted to go forward (weiter), backward (zurück) or repeat the step (wiederholen), because he might have misheard.
The first prototype solution, that I am showing above, is not perfect though, as we are not using a wake-up word. Instead we are offering the user periodically a chance to give us his input. The main drawback is that when the user speaks when it is not expected from him, we might not record it, and in consequence be unable to react to his inputs. Additionally sending audio back and forth in the cloud, creates a rather sluggish experience. I would be much happier to have the ASR part on the client directly especially when we are only listening to mainly 3-4 navigational words.
TTS with Slowsoft
Finally you have noticed above that there is a play method in the code above. That's where the TTS is hidden. As you see below we first show the speaker symbol in the application, signalling that now is the time to listen. We then send the text to Slowsoft via their API and in our case define the dialect "CHE-gr" and the speed and pitch of the output.
#play function
def play(self,text):
socketio.emit('showspeaker')
headers = {'Accept': 'audio/wav','Content-Type': 'application/json', "auth": "xxxxxx"}
with open("response.wav", "wb") as f:
resp = requests.post('https://slang.slowsoft.ch/webslang/tts', headers = headers, data = json.dumps({"text":text,"voiceorlang":"gsw-CHE-gr","speed":100,"pitch":100}))
f.write(resp.content)
os.system("mplayer response.wav")The text snippets are simply parts of the recipe. I tried to cut them into digestible parts, where each part contains roughly one action. Here having an already structured recipe in the open recipe format helps a lot, because we don't need to do any manual processing before sending the data.
Wakeup-word
We took our prototype for a spin and realized in our experiments that it is a must to have a wake-up. We simply couldn’t time the input correctly to enter it when the app was listening, this was a big pain for user experience.
I know that nowadays smart speakers like alexa or google home provide their own wakeup word, but we wanted to have our own. Is that even possible? Well, you have different options here. You could train a deep network from scratch with tensorflow-lite or create your own model by following along this tutorial on how to create a simple speech recognition with tensorflow. Yet the main drawback is that you might need a lot (and I mean A LOT as in 65 thousand samples) of audio samples. That is not really applicable for most users.
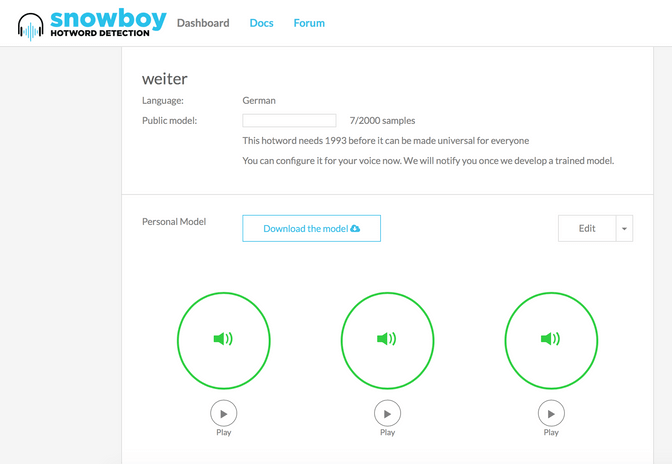
Luckily you can also take an existing deep network and train it to understand YOUR wakeup words. That means that it will not generalize as well to other persons, but maybe that is not that much of a problem. You might as well think of it as a feature, saying, that your assistant only listens to you and not your kids :). A solution of this form exists under the name snowboy, where a couple of ex-Googlers created a startup that lets you create your own wakeup words, and then download those models. That is exactly what I did for this prototype. All you need to do is to go on the snowboy website and provide three samples of your wakeup-word. It then computes a model that you can download. You can also use their REST API to do that, the idea here is that you can include this phase directly in your application making it very convenient for a user to set up his own wakeup- word.
#wakeup class
import snowboydecoder
import sys
import signal
class Wakeup():
def __init__(self):
self.detector = snowboydecoder.HotwordDetector("betty.pmdl", sensitivity=0.5)
self.interrupted = False
self.wakeup()
def signal_handler(signal, frame):
self.interrupted = True
def interrupt_callback(self):
return self.interrupted
def custom_callback(self):
self.interrupted = True
self.detector.terminate()
return True
def wakeup(self):
self.interrupted = False
self.detector.start(detected_callback=self.custom_callback, interrupt_check=self.interrupt_callback,sleep_time=0.03)
return self.interrupted
```
All it needs then is to create a wakeup class that you might run from any other app that you include it in. In the code above you’ll notice that we included our downloaded model there (“betty.pmdl”) and the rest of the methods are there to interrupt the wakeup method once we hear the wakeup word.
We then included this class in your main application as a blocking call, meaning that whenever we hit the part where we are supposed to listen to the wakeup word, we will remain there unless we hear the word:
```python
#integration into main app
...
#record
socketio.emit("showear")
wakeup.Wakeup()
socketio.emit("showmic")
text = recognize.RecognizeSpeech('myspeech.wav', 2)
…
```
So you noticed in the code above that we changed included the *wakeup.Wakeup()* call that now waits until the user has spoken the word, and only after that we then record 2 seconds of audio to send it to processing with wit.ai. In our testing that improved the user experience tremendously. You also see that we signall the listening to the user via graphical clues, by showing a little ear, when the app is listening for the wakeup word, and then showing a microphone when the app is ready is listening to your commands.
### Demo
So finally time to show you the Tech-Demo. It gives you an idea how such an app might work and also hopefully gives you a starting point for new ideas and other improvements. While it's definitely not perfect it does its job and allows me to cook handsfree :). Mission accomplished!
<figure class="video"><iframe allow="fullscreen" allowfullscreen src="https://player.vimeo.com/video/270594859"></iframe></figure>
## What's next?
In the first part of this blog post series we have seen quite an <a href="https://www.liip.ch/en/blog/betti-bossi-recipe-assistant-prototype-with-automatic-speech-recognition-asr-and-text-to-speech-tts-on-socket-io">extensive overview</a> over the current capabilities of TTS systems. While we have seen an abundance of options on the commercial side, sadly we didn’t find the same amount of sophisticated projects on the open source side. I hope this imbalance catches up in the future especially with the strong IoT movement, and the need to have these kind of technologies as an underlying stack for all kinds of smart assistant projects. Here is an <a href="https://www.kickstarter.com/projects/seeed/respeaker-an-open-modular-voice-interface-to-hack?lang=de">example</a> of a Kickstarter project for a small speaker with built in open source ASR and TTS.
In the <a href="https://www.liip.ch/en/blog/recipe-assistant-prototype-with-asr-and-tts-on-socket-io-part-2-ux-workshop">second blog post</a>, we discussed the user experience of audio centered assistants. We realized that going audio-only, might not always provide the best user experience, especially when the user is presented with a number of alternatives that he has to choise from. This was especially the case in the exploration phase, where you have to select a recipe and in the cooking phase where the user needs to go through the list of ingredients. Given that the <a href="https://www.amazon.de/Amazon-Echo-2nd-Generation-Anthrazit-Stoff-/dp/B06ZXQV6P8">Alexas</a>, <a href="https://www.apple.com/homepod/">Homepods</a> and the <a href="https://www.digitec.ch/de/s1/product/google-home-weiss-grau-multiroom-system-6421169">Google Home</a> smart boxes are on their way to take over the audio-based home assistant area, I think that their usage will only make sense in a number of very simple to navigate domains, as in “Alexa play me something from Jamiroquai”. In more difficult domains, such as cooking, mobile phones might be an interesting alternative, especially since they are much more portable (they are mobile after all), offer a screen and almost every person already has one.
Finally in the last part of the series I have shown you how to integrate a number of solutions together - wit.ai for ASR, slowsoft for TTS, snowboy for wakeupword and socket.io and flask for prototyping - to create a nice working prototype of a hands free cooking assistant. I have uploaded the code on github, so feel free to play around with it to sketch your own ideas. For us a next step could be taking the prototype to the next level, by really building it as an app for the Iphone or Android system, and especially improve on the speed of the ASR. Here we might use the existing <a href="https://developer.apple.com/machine-learning/">coreML</a> or <a href="https://www.tensorflow.org/mobile/tflite/">tensorflow light</a> frameworks or check how well we could already use the inbuilt ASR capabilities of the devices. As a final key take away we realized that building a hands free recipe assistant definitely is something different, than simply having the mobile phone read out the recipe out loud for you.
As always I am looking forward to your comments and insights and hope to update you on our little project soon.