

Intro
In one of our monthly innodays, where we try out new technologies and different approaches to old problems, we had the idea to collaborate with another company. Slowsoft is a provider of text to speech (TTS) solutions. To my knowledge they are the only ones who are able to generate Swiss German speech synthesis in various Swiss accents. We thought it would be a cool idea to combine it with our existing automatic speech recognition (ASR) expertise and build a cooking assistant that you can operate completely hands free. So no more touching your phone with your dirty fingers only to check again how many eggs you need for that cake. We decided that it would be great to go with some recipes from a famous swiss cookbook provider.
Overview
Generally there are quite a few text to speech solutions out there on the market. In the first out of two blog posts would like to give you a short overview of the available options. In the second blog post I will then describe at which insights we arrived in the UX workshop and how we then combined wit.ai with the solution from slowsoft in a quick and dirty web-app prototype built on socket.io and flask.
But first let us get an overview over existing text to speech (TTS) solutions. To showcase the performance of existing SaaS solutions I've chosen a random recipe from Betty Bossi and had it read by them:
Ofen auf 220 Grad vorheizen. Broccoli mit dem Strunk in ca. 1 1/2 cm dicke Scheiben schneiden, auf einem mit Backpapier belegten Blech verteilen. Öl darüberträufeln, salzen.
Backen: ca. 15 Min. in der Mitte des Ofens.
Essig, Öl und Dattelsirup verrühren, Schnittlauch grob schneiden, beigeben, Vinaigrette würzen.
Broccoli aus dem Ofen nehmen. Einige Chips mit den Edamame auf dem Broccoli verteilen. Vinaigrette darüberträufeln. Restliche Chips dazu servieren. But first: How does TTS work?
The classical way works like this: You have to record at least dozens of hours of raw speaker material in a professional studio. Depending on the task, the material can range from navigation instructions to jokes, depending on your use case. The next trick is called "unit-selection", where recorded speech is sliced into a high number (10k - 500k) of elementary components called phones, in order to be able to recombine those into new words, that the speaker has never recorded. The recombination of these components is not an easy task because the characteristics depend on the neighboring phonemes and the accentuation or prosody. These depend on a lot on the context. The problem is to find the right combination of these units that satisfy the input text and the accentuation and which can be joined together without generating glitches. The raw input text is first translated into a phonetic transcription which then serves as the input to selecting the right units from the database that are then concatenated into a waveform. Below is a great example from Apple's Siri engineering team showing how the slicing takes place.
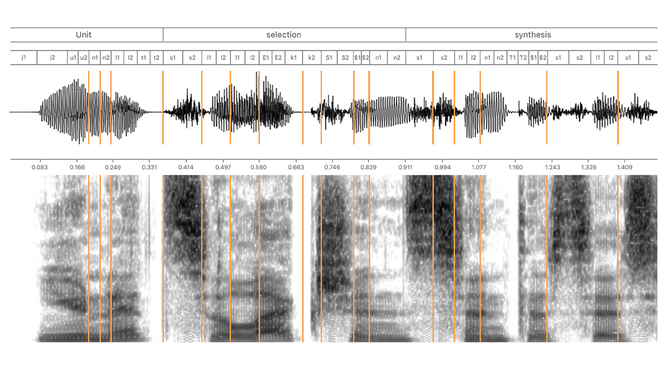
Using an algorithm called Viterbi the units are then concatenated in such a way that they create the lowest "cost", in cost resulting from selecting the right unit and concatenating two units together. Below is a great conceptual graphic from Apple's engineering blog showing this cost estimation.
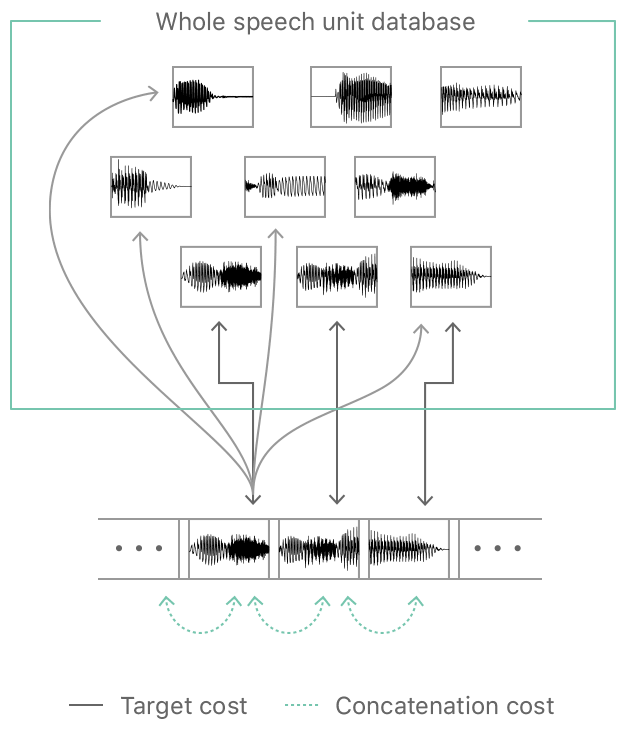
Now in contrast to the classical way of TTS new methods based on deep learning have emerged. Here deep learning networks are used to predict the unit selection. If you are interested how the new systems work in detail, I highly recommend the engineering blog entry describing how Apple crated the Siri voice. As a final note I'd like to add that there is also a format called speech synthetisis markup language, that allows users to manually specify the prosody for TTS systems, this can be used for example to put an emphasis on certain words, which is quite handy. So enough with the boring theory, let's have a look at the available solutions.
SaaS / Commercial
Google TTS
When thinking about SaaS solutions, the first thing that comes to mind these days, is obviously Google's TTS solution which they used to showcase Google's virtual assistant capabilities on this years Google IO conference. Have a look here if you haven't been wowed today yet. When you go to their website I highly encourage you to try out their demo with a German text of your choice. It really works well - the only downside for us was that it's not really Swiss German. I doubt that they will offer it for such a small user group - but who knows. I've taken a recipe and had it read by Google and frankly liked the output.
Azure Cognitive Services
Microsoft also offers TTS as part of their Azure cognitive services (ASR, Intent detection, TTS). Similar to Google, having ASR and TTS from one provider, definitely has the benefit of saving us one roundtrip since normally you would need to perform the following trips:
- Send audio data from client to server,
- Get response to client (dispatch the message on the client)
- Send our text to be transformed to speech (TTS) from client to server
- Get the response on client. Play it to the user.
Having ASR and TTS in one place reduces it to:
- ASR From client to server. Process it on the server.
- TTS response to client. Play it to the user.
Judging the speech synthesis quality, I personally I think that Microsoft's solution didn't sound as great as Googles synthesis. But have a look for yourself.
Amazon Polly
Amazon - having placed their bets on Alexa - of course has a sophisticated TTS solution, which they call Polly. I love the name :). To be where they are now, they have acquired a startup called Ivona already back in 2013, which were back then producing state of the art TTS solutions. Having tried it I liked the soft tone and the fluency of the results. Have a check yourself:
Apple Siri
Apple offers TTS as part of their iOS SDK in the name of SikiKit. I haven’t had the chance yet to play in depth with it. Wanting to try it out I made the error to think that apples TTS solution on the Desktop is the same as SiriKit. Yet SiriKit is nothing like the built in TTS on the MacOS. To have a bit of a laugh on your Macbook you can do a really poor TTS in the command line you can simply use a command:
say -v fred "Ofen auf 220 Grad vorheizen. Broccoli mit dem Strunk in ca. 1 1/2 cm dicke Scheiben schneiden, auf einem mit Backpapier belegten Blech verteilen. Öl darüberträufeln, salzen.
Backen: ca. 15 Min. in der Mitte des Ofens."While the output sounds awful, below is the same text read by Siri on the newest iOS 11.3. That shows you how far TTS systems have evolved in the last years. Sorry for the bad quality but somehow it seems impossible to turn off the external microphone when recording on an IPhone.
IBM Watson
In this arms race IBM also offers a TTS system, with a way to also define the prosody manually, using the SSML markup language standard. I didn't like their output in comparison to the presented alternatives, since it sounded quite artificial in comparison. But give it a try for yourself.
Other commercial solutions
Finally there are also competitors beyond the obvious ones such as Nuance (formerly Scansoft - originating from Xerox research). Despite their page promising a lot, I found the quality of the TTS in German to be a bit lacking.
Facebook doesn't offer a TTS solution, yet - maybe they have rather put their bets on Virtual Reality instead. Other notable solutions are Acapella, Innoetics, TomWeber Software, Aristech and Slowsoft for Swiss TTS.
OpenSource
Instead of providing the same kind of overview for the open source area, I think it's easier to list a few projects and provide a sample of the synthesis. Many of these projects are academic in nature, and often don't give you all the bells and whistles and fancy APIs like the commercial products, but with some dedication could definitely work if you put your mind to it.
- Espeak. sample - My personal favorite.
- Festival a project from the CMU university, focused on portability. No sample.
- Mary. From the german "Forschungszentrum für Künstliche Intelligenz" DKFI. sample
- Mbrola from the University of Mons sample
- Simple4All - a EU funded Project. sample
- Mycroft. More of an open source assistant, but runs on the Raspberry Pi.
- Mimic. Only the TTS from the Mycroft project. No sample available.
- Mozilla has published over 500 hours of material in their common voice project. Based on this data they offer a deep learning ASR project Deep Speech. Hopefully they will offer TTS based on this data too someday.
- Char2Wav from the University of Montreal (who btw. maintain the theano library). sample
Overall my feeling is that unfortunately most of the open source systems have not yet caught up with the commercial versions. I can only speculate about the reasons, as it might take a significant amount of good raw audio data to produce comparable results and a lot of fine tuning on the final model for each language. For an elaborate overview of all TTS systems, especially the ones that work in German, I highly recommend to check out the extensive list that Felix Burkhardt from the Technical University of Berlin has compiled.
That sums up the market overview of commercial and open source solutions. Overall I was quite amazed how fluent some of these solutions sounded and think the technology is ready to really change how we interact with computers. Stay tuned for the next blog post where I will explain how we put one of these solutions to use to create a hands free recipe reading assistant.