

Speech recognition is here to stay. Google Home, Amazon Alexa/Dot or the Apple Homepod devices are storming our living rooms. Speech recognition in terms of assistants on mobile phones such as Siri or Google home has reached a point where they actually become reasonably useful. So we might ask ourselves, can we put this technology to other uses than asking Alexa to put beer on the shopping list, or Microsoft Cortana for directions. For creating your own piece of software with speech recognition, actually not much is needed, so lets get started!
Overview
If you want to have your own speech recognition, there are three options:
- You can either hack Alexa to do things but you might be limited in possibilities
- You can use one of the integrated solutions such as Rebox that allows you more flexibility and has a microphone array and speech recognition built in.
- Or you use a simple raspberry pi or your laptop only. That’s the option I am going to talk about in this article. Oh btw here is a blog post from Pascal - another Liiper - showing how to do asr in the browser.
Speech Recognition (ASR) as Opensource
If you want to build your own device you make either use of excellent open source projects like CMU Sphinx, Mycroft, CNTK, kaldi, Mozilla DeepSpeech or KeenASR which can be deployed locally, often work already on a Raspberry Pi and often and have the benefit, that no data has to be sent through the Internet in order to recognize what you’ve just said. So there is no lag between saying something and the reaction of your device (We’ll cover this issue later). The drawback might be the quality of the speech recognition and the ease of its use. You might be wondering why it is hard to get speech recognition right? Well the short answer is data. The longer answer follows:
In a nutshell - How does speech recognition works?
Normally (original paper here) the idea is that you have a recurrent neural network(RNN). A RNN is a deep learning network where the current state influences the next state. Now you feed in 20-40 ms slices of audio that have been formerly transformed into a spectrogram as input into the RNN.
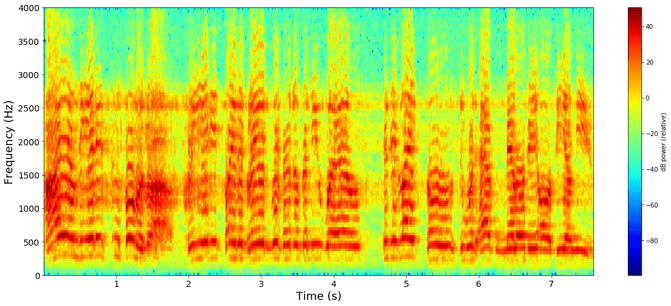
An RNN is useful for language tasks in particular because each letter influences the likelihood of the next. So when you say "speech" for example,the chances to say “ch” after you’ve said "spee" is quite high ("speed" might be an alternative too). So each 20ms slice is transformed into a letter and we might end up with a letter sequence like this: "sss_peeeech" where “” means nothing was recognized. After removing the blanks and combining the same letters into one we might end up with the word "speech", if we’re lucky and among other candidates like "spech", "spich", "sbitsch", etc... Because the word speech appears more often in written text we’ll go for that.
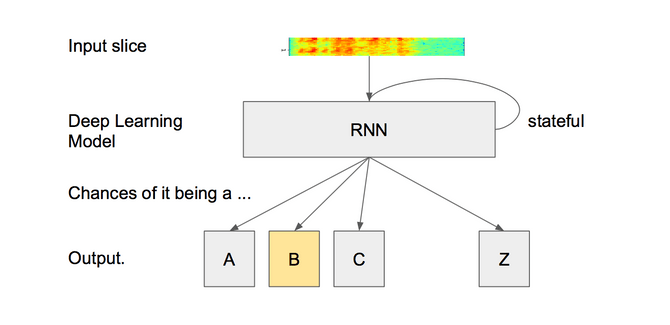
Where is the problem now? Well the problem is, you as a private person will not have millions of speech samples, which are needed to train the neural network. On the other hand everything you say to your phone, is collected by e.g. Alexa and used as training examples. You are not believing me? Here is all you have ever said samples to your Android phone. So what options are you having? Well you can still use one of the open source libraries, that already come with a pre-trained model. But often these models have been only trained for the english language. If you want to make them work for German or even Swiss-German you’d have to train them yourself. If you just want to get started you could use a speech recognition as a service provider.
Speech Recognition as a Service
If you feel like using a speech recognition service it might surprise you most startups in this area have been bought up by the giants. Google has bought startup api.ai and Facebook has bought another startup working in this field: wit.ai. Of course other big 5 companies are having their own speech services too. Microsoft has cognitive services in azure and IBM has speech recognition built into Watson. Feel free to choose one for yourself. From my experience their performance is quite similar. In this example I went with wit.ai
Speech recognition with wit.ai
For a fun little project "Heidi - the smart radio" at the SRF Hackathon (btw. Heidi scored 9th out of 30 :) I decided to build a smart little radio, that basically listens to what you are saying. You just tell the radio to play the station you want to hear and then it plays it. That’s about it. So all you need is a microphone and a speaker to build a prototype. So let’s get started.
Get the audio
First you will have to get the audio from your microphone, which can be done with python and pyaudio quite nicely. The idea here is that you’ll create a never ending loop which always records 4 seconds of your speech and saves it to a file after. In order to send the data to wit.ai, it reads from the file backa and sends it as a post request to wit.ai. Btw. we will do the recording in mono.
#speech.py
import pyaudio
import wave
def record_audio(RECORD_SECONDS, WAVE_OUTPUT_FILENAME):
#--------- SETTING PARAMS FOR OUR AUDIO FILE ------------#
FORMAT = pyaudio.paInt16 # format of wave
CHANNELS = 1 # no. of audio channels
RATE = 44100 # frame rate
CHUNK = 1024 # frames per audio sample
#--------------------------------------------------------#
# creating PyAudio object
audio = pyaudio.PyAudio()
# open a new stream for microphone
# It creates a PortAudio Stream Wrapper class object
stream = audio.open(format=FORMAT,channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)
#----------------- start of recording -------------------#
print("Listening...")
# list to save all audio frames
frames = []
for i in range(int(RATE / CHUNK * RECORD_SECONDS)):
# read audio stream from microphone
data = stream.read(CHUNK)
# append audio data to frames list
frames.append(data)
#------------------ end of recording --------------------#
print("Finished recording.")
stream.stop_stream() # stop the stream object
stream.close() # close the stream object
audio.terminate() # terminate PortAudio
#------------------ saving audio ------------------------#
# create wave file object
waveFile = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
# settings for wave file object
waveFile.setnchannels(CHANNELS)
waveFile.setsampwidth(audio.get_sample_size(FORMAT))
waveFile.setframerate(RATE)
waveFile.writeframes(b''.join(frames))
# closing the wave file object
waveFile.close()
def read_audio(WAVE_FILENAME):
# function to read audio(wav) file
with open(WAVE_FILENAME, 'rb') as f:
audio = f.read()
return audio
def RecognizeSpeech(AUDIO_FILENAME, num_seconds = 5):
# record audio of specified length in specified audio file
record_audio(num_seconds, AUDIO_FILENAME)
# reading audio
audio = read_audio(AUDIO_FILENAME)
# WIT.AI HERE
# ....
if __name__ == "__main__":
while True:
text = RecognizeSpeech('myspeech.wav', 4)Ok now you should have a myspeech.wav file in your folder that gets replaced with the newest recording every 4 seconds. We need to send it to wit.ai to find out what we've actually said.
Transform it into text
There is an extensive extensive documentation to wit.ai. I will use the HTTP API, which you can simply use with curl to try things out. To help you out in the start, I thought I'd write the file to show some of its capabilities. Generally all you need is an access_token from wit.ai that you send in the headers and the data that you want to be transformed into text. You will receive a text representation of it.
#recognize.py
import requests
import json
def read_audio(WAVE_FILENAME):
# function to read audio(wav) file
with open(WAVE_FILENAME, 'rb') as f:
audio = f.read()
return audio
API_ENDPOINT = 'https://api.wit.ai/speech'
ACCESS_TOKEN = 'XXXXXXXXXXXXXXX'
# get a sample of the audio that we recorded before.
audio = read_audio("myspeech.wav")
# defining headers for HTTP request
headers = {'authorization': 'Bearer ' + ACCESS_TOKEN,
'Content-Type': 'audio/wav'}
#Send the request as post request and the audio as data
resp = requests.post(API_ENDPOINT, headers = headers,
data = audio)
#Get the text
data = json.loads(resp.content)
print(data)So after recording something into your ".wav" file, you can send it off to wit.ai and receive an answer:
python recognize.py
{u'entities': {}, u'msg_id': u'0vqgXgfW8mka9y4fi', u'_text': u'Hallo Internet'}Understanding the intent
Nice it understood my gibberish! So now, the only thing left is to understand the intent of what we actually want. For this wit.ai has created an interface to figure out what the text was about. Different providers differ quite a bit on how to model intent, but for wit.ai it is nothing more than fiddling around with the gui.
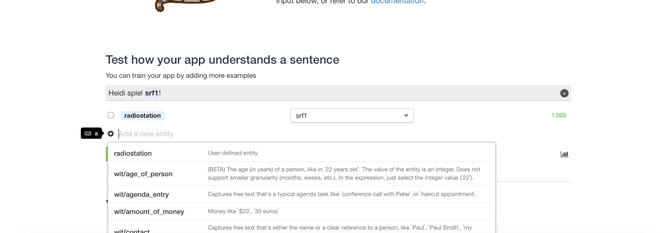
As you see in the screenshot wit has a couple of predefined entity types, such as: age_of_person, amount_of_money, datetime, duration, email, etc.. What you basically do is, to mark the word you are particularly interested about, using your mouse, for example the radio-station "srf1" and assign it to a matching entity type. If you can't find one you can simply create one such as "radiostation" . Now you can use the textbox to enter some examples and formulations and mark the entity to "train" wit to recognize your entity in different contexts. It works to a certain extent, but don't expect too much of it. If you are happy with the results, you can use the API to try it.
#intent.py
import requests
import json
API_ENDPOINT = 'https://api.wit.ai/speech'
ACCESS_TOKEN = 'XXXXXXXXXXXXXXX'
headers = {'authorization': 'Bearer ' + ACCESS_TOKEN}
# Send the text
text = "Heidi spiel srf1."
resp = requests.get('https://api.wit.ai/message?&q=(%s)' % text, headers = headers)
#Get the text
data = json.loads(resp.content)
print(data)So when you run it you might get:
python intent.py
{u'entities': {u'radiostation': [{u'confidence': 1, u'type': u'value', u'value': u'srf1'}]}, u'msg_id': u'0CPCCSKNcZy42SsPt', u'_text': u'(Heidi spiel srf1.)'}Obey
Nice it understood our radio station! Well there is not really much left to do, other than just play it. I've used a hacky mplayer call to just play something, but sky is the limit here.
...
if radiostation == "srf1" :
os.system("mplayer http://stream.srg-ssr.ch/m/drs1/aacp_96")
...Conclusion
That was easy wasn't it? Well yes, I omitted one problem, namely that our little smart radio is not very convenient because it feels very "laggish". It has to listen for 4 seconds first, then transmit the data to wit and wait until wit has recognized it, then find the intent out and finally play the radio station. That takes a while - not really long e.g. 1-2 seconds, but we humans are quite sensitive to such lags. Now if you are saying the voice command in the exact right moment when it is listening, you might be lucky. But otherwise you might end up having to repeat your command multiple times, just to hit the right slot. So what is the solution?
The solution comes in the form of a so called “wake word”. It's a keyword that the device listens constantly to and the reason why you have to say "Alexa" first all the time, if you want something from it. Once a device picks up its own “wake word”, it starts to record what you have to say after the keyword and transmits this bit to the cloud for processing and storage. In order to pickup the keyword fast, most of these devices do the automatic speech recognition for the keyword on the device, and send off the data to the cloud afterwards. Some companies, like Google, went even further and put the whole ml model on the mobile phone in order to have a faster response rate and as a bonus to work offline too.
What's next?
Although the "magic" behind the scenes of automatic speech recognition systems is quite complicated, it’s easy to use automatic speech recognition as a service. On the other hand the market is already quite saturated with different devices, for quite affordable prices. So there is really not much to win, if you want to create your own device in such a competitive market. Yet it might be interesting to use open source asr solutions in already existing systems, where there is need for confidentiality. I am sure not every user wants his speech data to end up in a google data center when he is using a third party app.
On the other hand for the big players offering devices for affordable prices turns out to be a good strategy. Not only are they so collecting more training data - which makes their automatic speech recognition even better - but eventually they are controlling a very private channel to the consumer, namely speech. After all, it’s hard to find an easier way of buying things rather than just saying it out loud.
For all other applications, it depends what you want to achieve. If you are a media company and want to be present on these devices, that will probably soon replace our old radios, then you should start developing so called "skills" for each of these systems. The discussion on the pros and cons of smart speakers is already ongoing.
For websites this new technology might finally bring an improvement for impaired people as most modern browsers seem more and more to support ASR directly the client. So it won't take too long, unless the old paradigm in web development will shift from "mobile first" to "speech first". We will see what the future holds.