

The big over-arching theme of the conference was human-machine collaboration: How can the results of an AI system be best communicated to its users. This touches topics like the perception, trust, and ethics of such AI systems. I was happy to see these questions at the core of the conference since they have been at our heart too for almost two years: See https://www.liip.ch/en/services/development/data.
In comparison to the last years, I had the impression that more and more corporations are also hooking up with the formerly mostly academic data-science community. That is an impression I had based on the number of booths and talks at the conference.
KeyNote
Ken Hughes gave an amazingly well-rehearsed keynote, that made me think about how the development of technology transcends our every-day-businesses or how he put it: Where silicon meets soul.
One of his key insights was that it is not enough to just satisfy the customer needs these days, but if companies can manage to give their users a tribal sense of belonging and provide more than their customers expect they can truly empower the customer. It might sound cliché but generally shifting towards a high consumer-centricity seems to be a thing not only for Jeff Bezos anymore.

Talks
The SDS conference offered up to seven simultaneous breakout session tracks - see the program here - which made it almost impossible to attend all of the talks that I was interested in.
There were technical tracks on Deep Learning and NLP containing lessons from hands-on experience with the newest AI models but there were also business-oriented tracks offering insights on integrating machine learning models into production. I was happy to see that there was a Data Ethics track, which created an opportunity for interested data scientists to discuss and shape the impact of AI models on society. Bravo to this! To get an feeling of what the trends are I attended presentations in different tracks. Here are my musings on the ones I attended. Feel free to check out the now available slides and recordings online here.
Principles and Best Practices for Applied Machine Learning Models
At Swiss Re, showed how the collective expertise and experience of numerous expert practitioners and managers from data science and risk management can be harnessed to to create a definitive set of principles and best practices that guides all our data science activities. In this talk they presented and discussed these principles and emphasized the principles which need much more care by the Data Scientist in industrial applications than in education and research.
I liked the birds-eye view segmenting those principles into “data-related”, “model-related”, “user-related” and “governance-related” areas, which forces us to think about all of these aspects at the same time.

Revenue Forecasting and Store Location Planning at Migros
The data scientists at Migros have presented their own algorithm that provides realistic revenue forecasts even for complex scenarios such as multiple new stores and/or alterations of the competitor store network. This algorithm combined a heuristic simulation of consumer behavior with machine learning methods to deliver both accurate and interpretable results.
It was interesting to learn how their in-house solution was developed in close collaboration with key users at Migros’ ten regional cooperatives. It bacame clear that interpretability for the planning expert was one of the main features that drove the adoption of the tool. Conrats to Bojan Škerlak from Migros, who won the Best Presentation award!

I was also excited to see that in order to create their tool they made use of a lot of open data from the BFS and SBB, which was then combined with their transactional cumulus data. In order to arrive at the end result, they ended up combining their “gravity model” with business logic to make the results more interpretable to the end-users.
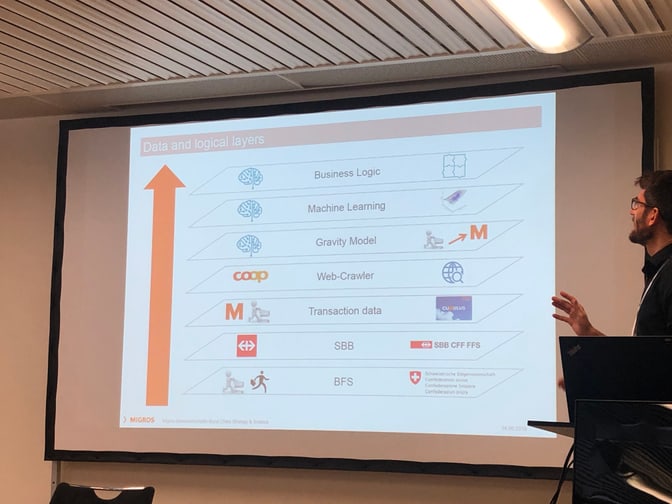
Do You Have to Read All Incoming Documents?
In the NLP track Mark Cieliebak showed how NLP solutions can be used to provide automatic classification of incoming documents into pre-defined classes (such as medical reports, prescriptions etc.) and then showed how to extract the relevant information for further processing. Using real-world examples, they have provided an overview of the potential applications, a realistic assessment of the effort and the resulting quality to be expected.
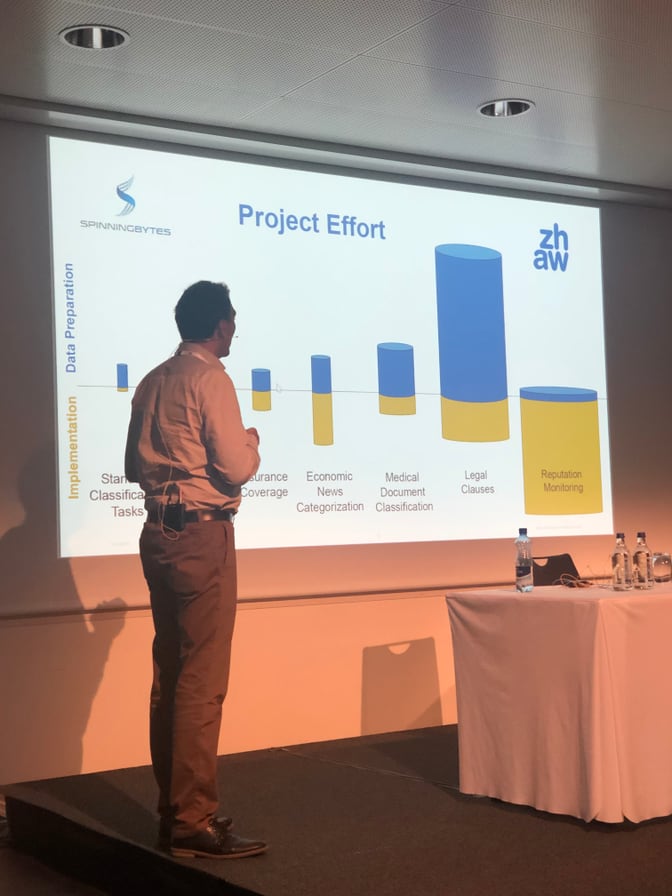
I particularly liked his assessment of the effort needed for data preparation and implementation in regards to the different project cases that they have encountered. Unsurprisingly when a business owner already has a huge corpus of annotated material that greatly reduces the data preparation part, and so allows the team to focus on an excellent implementation of the project.
Also combining supervised with unsupervised learning methods during training and data processing seemed to be an fruitful approach for classes where not enough data is available.

GPU Acceleration with RAPIDS for Traditional Big Data Analytics or Traditional Machine Learning
In the technical track René Müller gave a very interesting talk about how the RAPIDS suite provides the freedom to execute end-to-end data science and analytics pipelines entirely on GPUs. I liked how a simple python library can be used to accelerate common data preparation tasks for analytics and data science without running into typical serialization costs.

I was surprised how many classical algorithms already are implemented in their library (see screenshot below), yet many of those can only run on a single GPU (of course there is always (text: DASK link: https://dask.org/) . It is worth to note that when using a model that has been trained with RAPIDS one needs to also have a GPU to run it in inference mode, which makes them less portable.

If you are inclined to give it a try, you can either install it on your laptop (if it has a GPU) or simply try the fastest thing that works out of the box: This is a jupyter notebook in the google colaboratory wich even gives you T4 instances for free.
Creating Value for Clients through Data & Analytics
In this talk, Michel Neuhaus (Head of advanced analytics) and Daniel Perruchoud (Professor at FHNW) showed their journey towards a corporate environment focused on creating value through analytics for UBS and clients. They shared interesting insights from their track towards offering a collaborative work place for data science professionals.
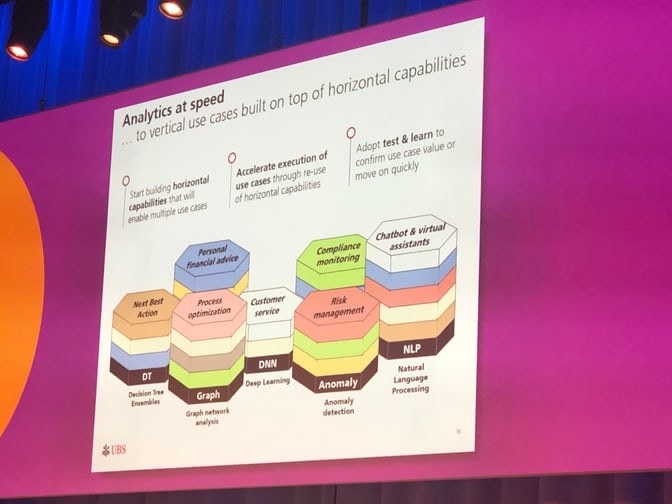
As an illustrative example, they have shown a simple use case of segmenting clients into groups of individuals with similar needs allowing us to offer the right service to the right client. I liked how they emphasized that the lessons learned along the way were embraced to drive the design and operation of the solution. For them, this meant going from a use-case oriented view to a vertical use case built on top of horizontal capabilities (see screenshot).
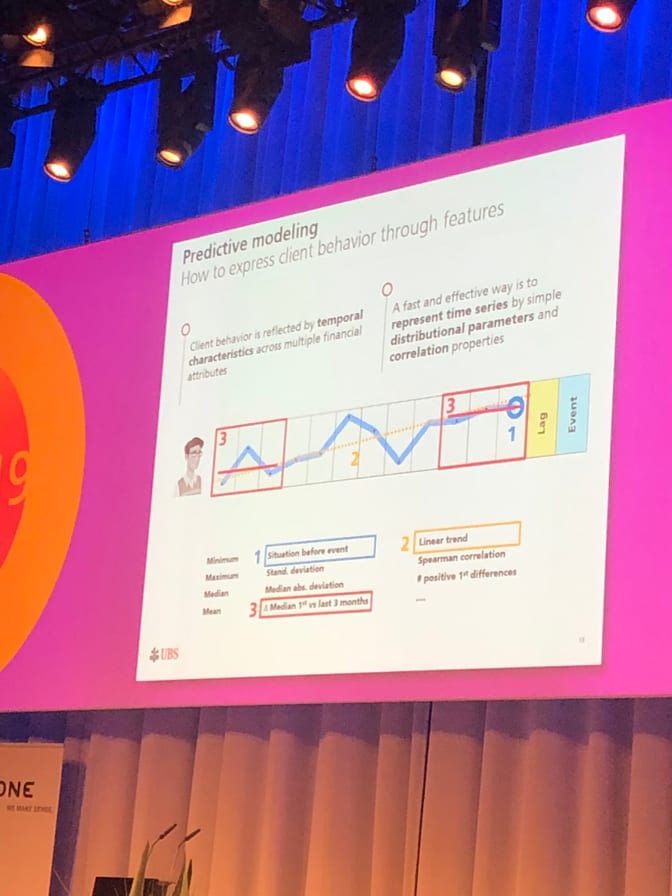
In the sample case that they provided, I liked how they were honest about how they modeled temporal client behavior, by just computing some very simple statistics, such as the minimum, mean, median or the average trend of a customers bank balance in time.
Final Thoughts
Overall the SDS 2019 was an excellent conference showing how the business applications and machine learning technologies are growing more closely together. Having seen a number of talks I am convinced that the winning formula of tech + business = ❤️ needs two additional components though: data and user experience.
Only if you really have the right data - and also have the right to use it in the way you intend to - you have a solid foundation for everything that builds on it. Collecting the right customer data and doing so in a way that preserves the user's privacy remains one of the biggest challenges today.
Focusing strongly on user experience is an aspect that gets neglected the most. Users are not interested in technology but instead in improving their user experience, thus any new type of algorithm has only one goal: to improve the user’s experience. Only then is the final result perceived as useful can stand a chance against the existing status quo.
So coming back to the key-note this means that indeed successful projects are those that use the existing ML-technology to delight, engage and empower the users.