

In a recent innovation project, we had the challange to help users better understand news articles. I want to share our approach and findings.
Idea
During a brainstorming session, the idea came up to augment text to give users explainations for terms and abbreviations used in news articles. The inspiration for this was Genius (formerly Rap Genius). Unlike Genius we wanted the terms and explanations to be automatically generated instead of needing users to provide them.
This is a mockup of the proposed feature on a mobile device:

The workflow of a user is as follows:
- A user is referred to a news article on their social media platform
- On the news article the terms, abbreviations, persons etc. are highlighted in yellow to indicate "extra content"
- If a user hovers (on a desktop computer) or clicks (on mobile) on a term, the extra information is displayed
This "extra content" helps the user to navigate the article by showing the important parts and provides help where it could be useful.
If the user is known (e.g. because they are logged it), it would even be possible to personalize the content and terms. So that a topic expert gets more in-depth information than the casual reader.
Architecture
The prototype was setup deliberately as a standalone application with no direct integration of the news site. This was due to the project setup as there were no technical resources available at the client side for this project. Therefore we decided to setup a reverse proxy to get the original news website and inject a bit of JavaScript to augment the page. This approach has been proven to be very good, as the client can see the changes directly on "their" page, without having to deal with their internal IT and possible restrictions. For our innovation project this was exactly right, as it allowed us to move quickly and deliver meaningful results.
We quickly realized that simply invoking some JavaScript was not enough to get the task done, as there are many complex steps until a result is ready. For the prototype we focused on English text only.
These are the components we identified:
- Reverse proxy - to get the original content
- Extract text - get the article text from the HTML of the website
- Named-Entity-Recognition (NER) - extract the important terms/entities from the extracted text
- Search - provide an explaination of the terms/entities from the NER
- Highlight - highlight the terms and display the extra content provided by the search
To have a maximum of flexibility, we decided to use a Message queue. All of these steps need an input, can then work independently and produce an output. So using a message queue was a natural choice. The steps can run asychronously and can even be written in completely different languages.
For the sake of this prototype we created multiple implementation for some compontents:
- Extract text
- unfluff (JavaScript)
- Beautiful Soup (Python)
- Named-Entity-Recognition
- NLTK (Python)
- OpenCalais (Python)
- Search
Here is a sequence diagram to explain in more detail how a user gets a result in the prototype:
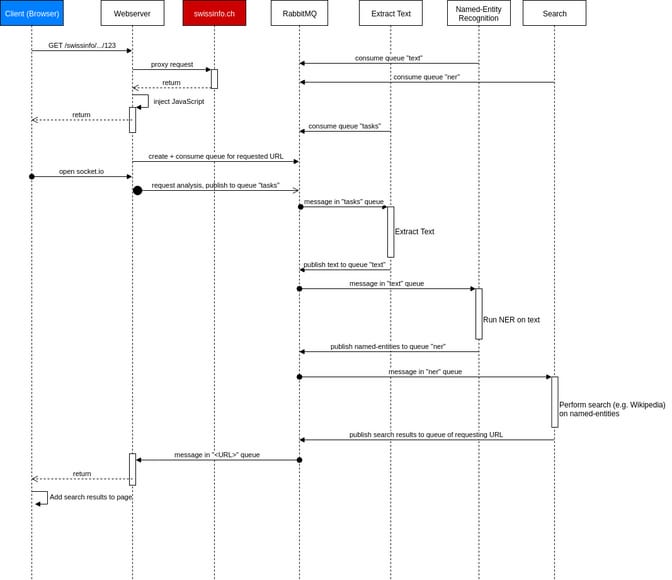
Note that for the communication between the client (browser) and the server we chose socket.io. It establishes a long-standing connection to send and receive events, if possible it makes use of web sockets.
Findings
Extract text
This is a step that would not be necessary in a production environment, as we would have first-class access to the text.
Named-Entity-Recognition
Depending on the topic of a news article the results varyied a lot. OpenCalais could shine on all economic topics, but lacked knowledge of Swiss politicians or local events. NLTK gets the job nicely done, even though a lot of important terms are still missing. To make sure certain things are always covered (like commonly used abbreviations), we would propose to create a controlled vocabulary and always check for these terms as an additional step.
Search
The search on Wikidata needs more context of the text than we currently provide. The content is high quality, but with our simplistic approach the results are often either too general ("Switzerland is a country in Western Europe") or wrong (e.g. information about a famous person sharing the same lastname as someone in the article).
So the search definitely needs more information to return better results.
Nonetheless this prototype showed a great potential for the general idea, it helps us to develop an architecture to quickly combine components written in different languages and last but not least a clever approach to integrate a prototype in an existing website without interference as you can see on this screenshot:

For details, check the code of the protoype.