

"The cloud"

The usual joke is that "the cloud" is just someone else's computer - it is actually much more than that. It allows to develop programs that are able to work at scale. Even better to work without having to worry about adding new physical servers and memory. This also means that the development paradigm is different. First, the way you think about the interactions between the application and the server needs to be adjusted. In the mobile world, it also provides tools that allow synchronizing data much more easily than with the usual client-server patterns.
When we decided to work on Scrawl, we wanted to use serverless tools only - now we see where it leads us. The most common platform and easiest to integrate was Firebase from Google. That’s why we decided to give it a go. Our experience should likely be the same with other providers such as Amplify from Amazon or Azure from Microsoft.
In this blog post, I highlight some of the challenges we encountered and show how you will overcome them.
Our setup
The concept of the game is the following:
- Create a game against another player
- Make a drawing of a word that has been given to you randomly
- Our custom AI tries to recognize the two drawings
- The player with the most legible drawing wins !
If you haven't already, download Scrawl on your iPhone.
We used three services from Firebase:
- Authentication to allow users to login to the game with their email or Google account
- Cloud Firestore to store user and game data
- Cloud Functions to be able to run code on the server's data
Now, let's get into the specifics!
You don't control the server
While this seems obvious, some implications are not. As a developer, you write code that will be executed on a remote server. However, the server management is at the service provider. The goal of the service provider is to let you run your code and minimize the running costs. If your app is heavily used, they will add servers to support the load. But if your app is not used, they can also choose to kill your code completely. And that’s what happened to us in production.
When an account is created, we run a cloud function to initialize it. We set the points to 0, we generate a random gamer name, etc...
After the user created their account, we show the main screen in the app. That’s where we can see the player data. This works perfectly if our code is ready on the server side (hot start). However, it will break if our server side has to start (cold start). In our case, it took around three seconds to boot and initialize the user's data. Three seconds does not seem too bad, but it is already too much. The app gets stuck because it cannot find the user's profile and stays in the "login" screen.
Note: there are ways to prevent your app to be completely shut down, which we did not anticipate.
Learning: Make sure that your app will continue working even though the server is not ready to react to your changes.
You don't control the execution
Since your code is automagically scaled by the provider, it can happen that your cloud function is called more than once with the same parameters. All your code has to be idempotent. Which means that, even if the code is called more than once, the end result should not change.
In Scrawl, we try to identify the drawing after a user finished their drawing on the device. Afterwards, we write the results in the local database. The local database is automatically replicated to the server by the Firestore library. On the server side, we have a function that reacts to new "results" documents and finds the winner between the two players. After the winner is defined, we have to update their leaderboard score to match their new victory.
When this function was called twice, we had cases where the points were added twice to the user's profile! It is nice for the winner, but unfair to the others.
Learning: all you code has to be idempotent. Don't make it too complex.
Don't use it for everything
When all you have is a hammer, everything looks like a nail
Our goal was to try (and have fun) with Firestore and cloud functions. That’s why everything that needed an interaction with the server was done with those tools, even if it was more convoluted.
Here is a very specific example: when a player creates a game against another player, we have to randomly select a word that the players will have to draw. This obviously has to be done on the server side to prevent cheating. Our first attempt was:
- Create a document in our local Firestore instance with both players IDs
- Wait for the synchronization to the server (instantaneous, but still has to be done)
- Cloud function picks up the new document, and creates a new game
- App waits asynchronously until a new game has been created for the user
- Play
This works but, it creates a lot of unnecessary asynchronicity and adds more risks of failing. Firebase Cloud Functions also allows to create HTTP endpoints, so we created one for that - following this process:
- Do a POST call with both players IDs and wait synchronously for the answer
- Server gets the request and creates a new game
- Play
Learning: think about your use cases and only apply the new technology to places that benefit from it.
Modeling your data can be tricky with Firestore
At first, we wanted to have a simple data model: we have users and games - that's it.
And then there was a problem. We don't have an HTTP call from the app to the backend, then the backend writes to the database. It is the devices themselves that write to the database. In our case, we want the devices to communicate their drawing values, but we don't want them to be able to change the score.
For this, we decided to have multiple documents:
- one "game" document that is readable by everyone, but writable only by the backend
- two "results" documents, that are writable by the respective players
With this, the devices would be able to write on their own documents, and the backend could select the winner. Everyone could then read the "game" document and display the winner.
But then there was another problem: the "game" document did not contain the drawing values from the devices anymore, since they were reported somewhere else. The devices could display the winner, but not the "percentages" you see in the results screen.
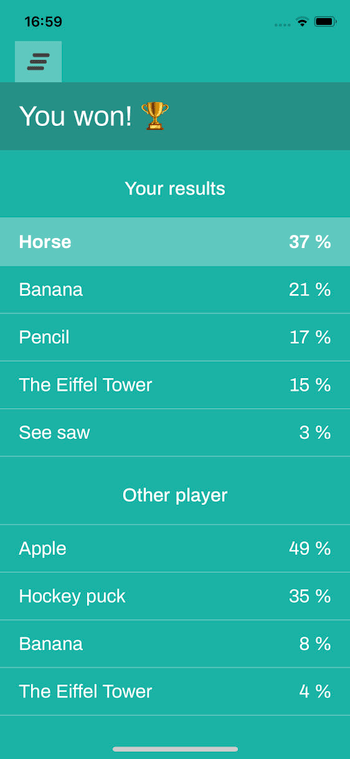
So we went for another trick: once the backend detects new "results" documents, it copies its content in the "game" document so that everything is readily available from both devices.
In this case copying data - called denormalization - is perfectly acceptable, however this might not be the perfect solution.
Learning: data modeling and security rules have to be well-thought from the beginning.
Conclusion
Working on Scrawl was great fun. We discovered lots of technologies and collaborated between three Liip offices.
As with any new technology, we found quirks we had to work around. Clearly, we did not discover a silver bullet. However it could be very useful for specific use cases.
And for now, gold old boring technology does the trick for us!
Header photo by Pero Kalimero on Unsplash.
"There is no cloud": CC-BY-SA 4.0 FSFE.org