

Let's consider two examples:
- Anna wants to compare real estate prices in Bern and Zurich. She stumbles upon an open data portal of Switzerland. There is a dataset of the Statistical Office of the City of Zurich covering the real estate prices, unfortunately there is no such dataset for Bern. Anna will try to find those using the search.
- Thomas wants to have a look at the Outcomes of the recent votings (“Ständeratswahlen”) in Zürich and wants to know how each of the prominent politicians performed.
We have taken the assumption, that a user of such a portal is interested in certain data, but doesn’t know where to find it. They are not familiar with the portal nor are they considered “power users” with special knowledge about the data or metadata.
To make things more exciting we have written this blog post with two authors: Stefan Oderbolz and Thomas Ebermann. Stefan will try to convince you that a search based on metadata will help Anna greatly to find her the right dataset to compare real estate prices. Thomas will try to convince you that a search on primary data will work better for Thomas and allow him to quickly find the right dataset.
While we rolled a dice who will have to write which part, we will try as hard as we can to convince you - the reader - that our opinion is the best. Buckle up and enjoy the ride.
Why we need Metadata-based search
by Stefan Oderbolz
Metadata-based search means, the search engine, that powers a portal search has indexed documents based on a specified metadata schema. Documents have metadata fields like title, description, keywords or temporal and spatial coverage.
In its most basic form, a query for “Zurich real estate” will return all documents, that have metadata values matching the “Zurich” “real” and “estate”.
“Zurich” will be covered by the spatial coverage field. “Real” and “estate” resp. “Real estate” are either found as keywords or as part of the title and description of the dataset.
Anna’s search will return 2 results:
- The aforementioned dataset of the Statistical Office of the City of Zurich
- A dataset of the Canton of Zurich, that contains the real estate data for the whole Canton (incl. The City of Zurich)
No further results are shown. The analogous search “Bern real estate” doesn’t return any datasets.
This example shows the strength of the metadata-based search: if the metadata has good quality, you get the correct datasets. And if the search does not return anything, you can be confident, that the dataset does not exist (by-the-way: this would be a good time to start a “data request” for this data, so next time you search, you’ll find both datasets right away).
I think this is an important message: getting zero results is actually a good thing. You know it’s not there. This heavily relies on the assumption that the metadata is good and correctly indexed.

A neatly organized catalogue helps the users to browse it, without even entering search terms. You can show categories for your datasets, to give information about what kind of things you can find on the portal.
A neatly organized catalogue helps the users to browse it, without even entering search terms. You can show categories for your datasets, to give information about what kind of things you can find on the portal.
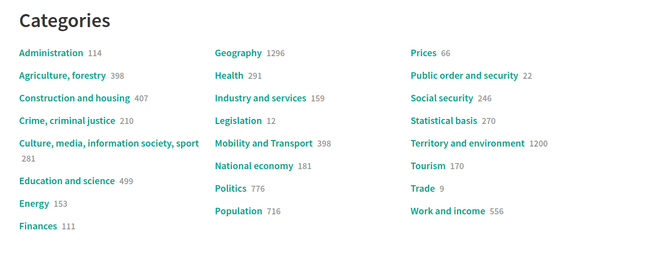
With keywords on each dataset you can even create this on a more fine-grained level. A user might discover similar datasets, that share the same keyword (see screenshot below). Like this a user has the possibility to “move” seamlessly in the catalogue and discover the available datasets.
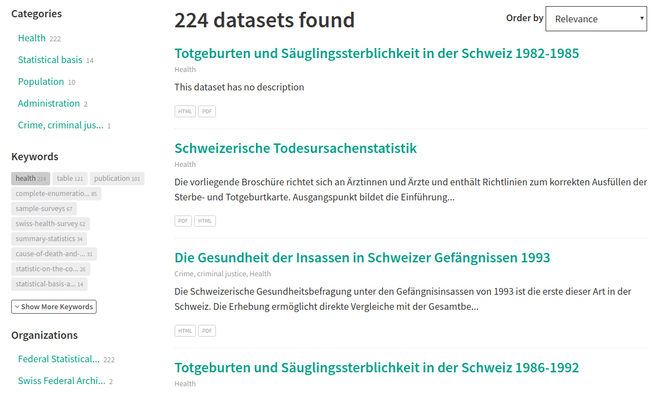
Last but not least the metadata-based approach forces data publishers to deliver high quality metadata for each dataset. Otherwise nobody will find and use the datasets. This incentive is important to keep in mind. If we simply outsource the task to the computer, we lose all the valuable knowledge the publishers have of their data. For the closed world of a data portal, this is a source we can not afford to lose.
The catch-all primary-data approach might be the right choice for something vast like the web, but not for the small-ish, precise area of a data catalogue. But I’ll let Thomas take it from here and convince you otherwise.
Why we will need primary-data search
By Thomas Ebermann
Let's go back in time. Let’s go way back, even before pokemon go was popular, maybe let's go even to a time where pokemon didn’t even exist. In that distant past somewhere around 1996 we lived in a different world. In a world without Trump and chaos. In a world where there things were somewhat ordered.
If you wanted a book you went to your local library - and if you had an old library like me: without a computer, then could go to an even then weird place, called an index-catalogue, where you could look for books containing a certain author, or you could look at books for a certain genre, for example fantasy literature. If you felt even a bit adventurous you could as well wonder through the library only to find that all of the books were nicely put into categories and have been alphabetized by the authors name. It was a nice experience. But it was also a tedious one.

The web was no different. We were living at the time, where looking for a website was really easy. You just had to do the same things that you did in your library. Go to an index-catalogue - I mean Yahoo - and then select the right category, for example Recreation - Health and Sports and there you would find all of the websites about soccer or american football. It was simple, it was effective, life was good.
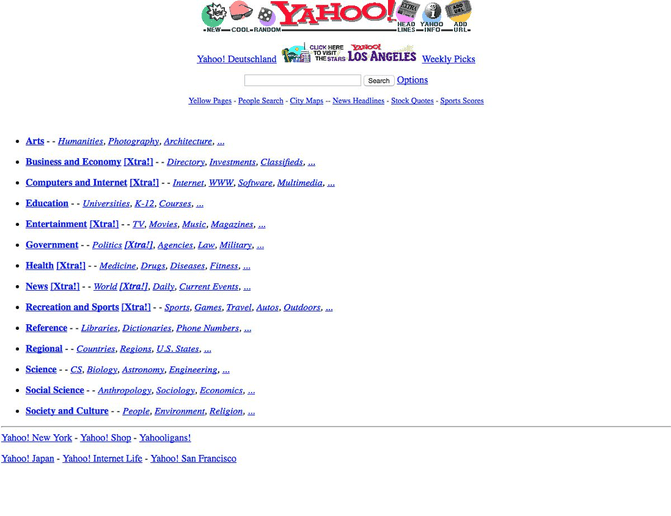
But of course someone had to ruin it. It was us, we just liked making websites too much. More and more websites emerged, and soon there was no simple fast way to categorize them all. It was like a library that instead of receiving 10 new books a day all of a sudden received 1 Million a day. Nobody could categorize it all, nobody could read it all.
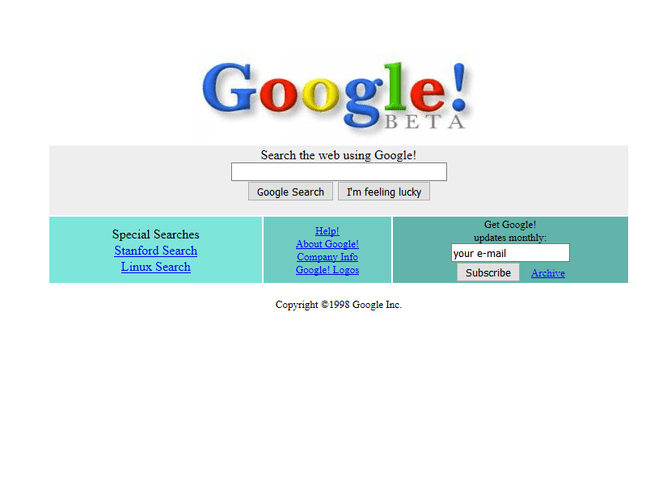
And then Google came to save us. It was drastic. They had thrown away all of the categories, folders and myriads of subfolders, that librarians had worked so hard on. Instead they just gave us a search box. That was it. And the most ridiculous thing happened. People actually liked it. The results were relevant and fast. It was almost magic, like a librarian that knew it all. Like a librarian that had actually read all the books and knew what was inside them.
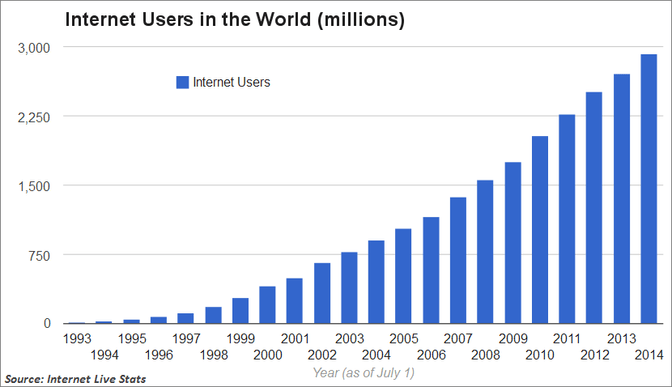
Moving forward 20 years here we stand, and I still feel reminded of my good old library when I think of opendata.swiss. Looking at the nearly 7000 datasets on opendata swiss it makes me proud how fast the amount of datasets has risen. In 2016 the amount of datasets was nearly half that number, I still remember that website having a big two...something on the frontpage.
While we cannot simply assume that the amount of open datasets will rise as quickly as the amount of websites or internet users, I still expect that rather sooner than later we will have 100 000 datasets on open data worldwide. At this point it will definitely be a burden to go and find these datasets via a catalogue. We will definitely rely on the big search box more.
We will probably expect even more from that searchbox. Similarly to Google, who has become a librarian who has read all the websites, we probably will also want a librarian who has read all of our datasets.
So when I type in “Limmatstrasse” into that box, I will somehow expect to find every dataset that has to do with Limmatstrasse. Probably those that are really popular to be on the top of my search results and those that are less popular to be at the back.
While I eventually might want to facet my search, so for example just have datasets on related to politics, I might as well enter “Limmatstrasse Kantonsratswahlen 2018 Mauch” or something into the box and find what I needed, when I am looking for a dataset containing the candidates and some sort of breakdown on the regions.
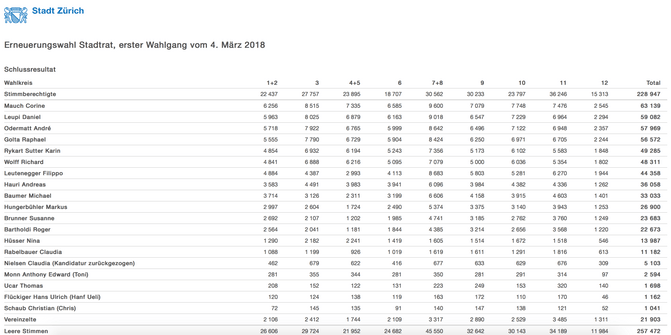
Being a lazy person I might expect, that a click on that search result will take me directly into the relevant rows of the dataset, just to verify that that's the right thing that I want.
Yet all of these things are not possible when relying only on a metadata for my search. First of all, I will probably get lost in the catalogue when trying to go through 100 000 datasets. Second, I probably won’t find even one dataset containing Limmatstrasse, because nobody cared to enter myriads of different streets into the metadata. It's just not practical. The same goes for all involved candidates. Nobody has the time nor resources to annotate the dataset that thoroughly. Finally it's simply impossible to point me at the right row in a dataset when all I have is just some metadata.
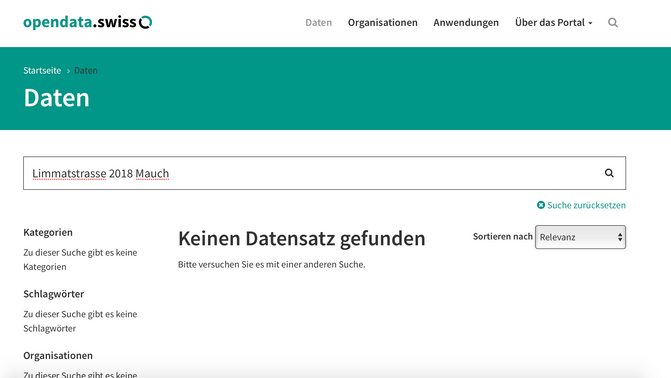
So while everybody who submitted his dataset did a fairly good job at annotating it, it's simply not enough to fulfill my needs. I need a librarian who, similarly to Google back in the 90ties, has a radically different approach. I will need a librarian who has read all of the datasets that are in the library and can point me to the right dataset, even if my query very rather fuzzy. In other words I need a search that has indexed all of the primary data.
Conclusion: best of both worlds
So there we are, you have seen the high flying arguments from both worlds while each us us has swiped the negative aspects of each solutions under the table. So here they are:
- Downsides of Metadata for search:
- It’s relevant when you want to make sense out of the primary data but it will never be as rich as the primary data. It obviously does not contain some aspects that a user might be searching for.
- There is a constant dissonance between what the users are searching for and how we tag things (e.g. “weather” vs. meteodata, or “Lokale Informationen” vs. Zürich)
- Downsides of Primary Data for search:
- On the other side primary data might match a lot of relevant search terms that the user is searching for, but it is simply not good for abstraction (e.g. I want all the data from all swiss cities).
- Creating such ontologies from primary data is very difficult: Thus automatically tagging datasets based on primary data into categories like health or politics is hard.
- Using only primary data we might also run into the problem of relevancy. When a user is searching for a very generic keyword like Zürich, and then finds myriads or results that have the word Zürich and yet cannot facet his search down only to political results is frustrating.
Precision and Recall
So of course from our perspective a perfect search will have to embrace both worlds. To formalize that a bit let's think about recall and precision.
- Recall: How many datasets that are relevant have been found? (If 10 are potentially relevant but the search returns only one, thats a low recall)
- Precision: How many datasets that have been returned are relevant? (If 10 datasets have been returned, but only 1 is actually relevant, thats a low precision)
So in an ideal world we would want a search to have both, but the reality today looks more like this:
| Precision | Recall | |
| Metadata Search | High | Low |
| Primary-data Search | Low | High |
| Combined Approach | High | High |
So while metadata search has a high precision, because you only get what you search for, it lacks in recall, often not finding all of the relevant datasets, just because they have been tagged badly. On the other hand a primary-data search gives you a high recall, e.g. returning all of the datasets that somewhere have the word “Zürich” in it, but has a low precision because probably most of the search results are not really relevant for you.
There are also two other arguments where the primary data and meta-data approach differ: On one hand indexing primary data allows us to search for “Limmatstrasse Kantonsratswahlen 2018 Mauch”, so giving us a very fine grained information retrieval. On the other hand just using primary data to “browse” a catalogue is not useful. In contrast using metadata, searching for “Politics” or “Votings” we rather get a very broad result set. Yet using those tags to browse into “Politik” and “Abstimmungen” might give us a much wider overview of available datasets that go beyond our little search.
| Good for | Poor for | |
| Metatdata Information | Browsing the catalogue | Highly detailed search queries |
| Primary-data Information | Highly detailed search queries | Browsing the catalogue |
That's why we think that in the future we should embrace indexing primary data of our datasets while combining it smartly with the metadata information, to really get the best of both world. While this might not be easy, especially having a high precision and a high recall, we think it is a challenge worth trying. I am very sure that it will improve the overall user experience. After all we want all these precious datasets to be found and used.