

Part 1: SaaS vendors
This article is the first part of a series. Make sure to subscribe to receive future updates!
TLDR: If you want to use the API's as fast as possible, directly check out my code on GitHub.
Did you ever had the need for face detection?
Maybe to improve image cropping, ensure that a profile picture really contains a face or maybe to simply find images from your dataset containing people (well, faces in this case).
Which face detection SaaS vendor would be the best for your project? Let’s have a deeper look into the differences in success rates, pricing and speed.
In this blog post I'll be analyzing the face detection API's of:
How does face detection work anyway?
Before we dive into our analysis of the different solutions, let’s understand how face detection works today in the first place.
The Viola–Jones Face Detection
It’s the year 2001. Wikipedia is being launched by Jimmy Wales and Larry Sanger, the Netherlands becomes the first country in the world to make same-sex marriage legal and the world witnesses one of the most tragic terror attacks ever.
At the same time two bright minds, Paul Viola and Michael Jone, come together to start a revolution in computer vision.
Until 2001, face detection was something which didn’t work very precise nor very fast. That was, until the Viola-Jones Face Detection Framework was proposed which not only had a high success rate in detecting faces but could do it also in real time.
While face and object recognition challenges existed since the 90’s, they surely boomed even more after the Viola–Jones paper was released.
Deep Convolutional Neural Networks
One of such challenges is the ImageNet Large Scale Visual Recognition Challenge which exists since 2010. While in the first two years the top teams were working mostly with a combination of Fisher Vectors and Support vector machines, 2012 changed everything.
The team of the University of Toronto (consisting of Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton) used for the first time a deep convolutional neural network for object detection. They scored first place with an error rate of 15.4% while the second placed team had a 26.2% error rate!
A year later, in 2013, every team in the top 5 was using a deep convolutional neural network.
So, how does such a network work?
An easy-to-understand video was published by Google earlier this year:
What do Amazon, Google, IBM and Microsoft use today?
Since then, not much changed. Today’s vendors still use Deep Convolutional Neural Networks, probably combined with other Deep Learning techniques though.
Obviously, they don’t publish how their visual recognition techniques exactly work. The information I found was:
- Amazon: Deep Neural Networks
- Google: Convolutional Neural Network
- IBM: Deep Learning algorithms
- Microsoft: Face algorithms
While they all sound very similar, there are some differences in the results.
Before we test them, let’s have a look at the pricing models first though!
Pricing
Amazon, Google and Microsoft have a similar pricing model, meaning that with increasing usage the price per detection drops.
With IBM however, you always pay the same price per API call after your free tier usage volume is exhausted.
Microsoft provides you the best free tier, allowing you to process 30'000 images per month for free.
If you need more detections though, you need to use their standard tier where you start paying from the first image on.
Price comparison
That being said, let’s calculate the costs for three different profile types.
- Profile A: Small startup/business processing 1’000 images per month
- Profile B: Digital vendor with lots of images, processing 100’000 images per month
- Profile C: Data center processing 10’000’000 images per month
| Amazon | IBM | Microsoft | ||
|---|---|---|---|---|
| Profile A | $1.00 USD | Free | Free | Free |
| Profile B | $100.00 USD | $148.50 USD | $396.00 USD | $100.00 USD |
| Profile C | $8’200.00 USD | $10’498.50 USD | $39’996.00 USD | 7’200.00 USD |
Looking at the numbers, for small customers there’s not much of a difference in pricing. While Amazon charges you starting from the first image, having 1’000 images processed still only costs one Dollar. However, if you don’t want to pay anything, then Google, IBM or Microsoft will be your vendor to go.
Note: Amazon offers a free tier on which you can process 5’000 images per month for the first 12 months for free! However, after this 12 month trial, you’ll have to start paying starting with the first image.
Large API usage
If you really need to process millions of images, it's important to compare how every vendor scales.
Here's a list of the minimum price you pay for the API usage after a certain amount of images.
- IBM constantly charges you $4.00 USD per 1’000 images (no scaling)
- Google scales down to $0.60 USD (per 1’000 images) after the 5’000’000th image
- Amazon scales down to $0.40 USD (per 1’000 images) after the 100’000’000th image
- Microsoft scales down to $0.40 USD (per 1’000 images) after the 100’000’000th image
So, comparing prices, Microsoft (and Amazon) seem to be the winner.
But can they also score in success rate, speed and integration? Let’s find out!
Hands on! Let’s try out the different API’s
Enough theory and numbers, let’s dive into coding! You can find all code used here in my GitHub repository.
Setting up our image dataset
First things first. Before we scan images for faces, let’s set up our image dataset.
For this blog post I’ve downloaded 33 images from pexels.com, many thanks to the contributors/photographers of the images and also to Pexels!
The images have been committed to the GitHub repository, so you don't need to search for any images if you simply want to start playing with the API's.
Writing a basic test framework
Framework might be the wrong word as my custom code only consists of two classes. However, these two classes help me to easily analyze image (meta-) data and have as few code as possibly in the different implementations.
A very short description: The FaceDetectionClient class holds general information about where the images are stored, vendor details and all processed images (as FaceDetectionImage objects).
Comparing the vendors SDK’s
As I’m most familiar with PHP, I've decided to stick to PHP for this test. I still want to point out what SDK’s each vendor provides (as of today):
| Amazon | IBM | Microsoft | |
|---|---|---|---|
|
|
|
|
Note: Microsoft doesn't actually provide any SDK's, they do offer code examples for the technologies listed above though.
If you’ve read the lists carefully, you might have noticed that IBM does not only offer the least amount of SDK’s but also no SDK for PHP.
However, that wasn’t a big issue for me as they provide cURL examples which helped me to easily write 37 lines of code for a (very basic) IBM Visual Recognition client class.
Integrating the vendors API’s
Getting the SDK's is easy. Even easier with Composer. However, I did notice some things that could be improved to make a developer’s life easier.
Amazon
I've started with the Amazon Rekognition API. Going through their documentation, I really felt a bit lost at the beginning. Not only did I miss some basic examples (or wasn’t able to find them?), but also I had the feeling that I have to click a few times until I was able to find what I was looking for. In one case I even gave up and simply got the information by directly inspecting their SDK source code.
On the other hand, it could just be me? Let me know if Amazon Rekognition was easy (or difficult) for you to integrate!
Note: While Google and IBM return the bounding boxes coordinates, Amazon returns the coordinates as ratio of the overall image width/height. I have no idea why that is, but it's not a big deal. You can write a helper function to get the coordinates from the ratio, just as I did.
Next came Google. In comparison with Amazon, they do provide examples, which helped me a lot! Or maybe I was just already in the “investing different SDK’s” mindset.
Whatever the case may be, integrating the SDK felt a lot simpler and also I had to spend less clicks to retrieve information I was looking for.
IBM
As stated before, IBM doesn’t (yet?) provide a SDK for PHP. However, with the provided cURL examples, I had a custom client set up in no time. There’s not much that you can do wrong if a cURL example is provided to you!
Microsoft
Looking at Microsoft's code example for PHP (which uses Pear's HTTP_Request2 package), I ended up writing my own client for Microsoft's Face API.
I guess I'm simply a cURL person.
Inter-rater reliability
Before we compare the different face detection API’s, let's scan the images first by ourselves! How many faces would a human be able to detect?
If you already had a look on my dataset, you might have seen a few images containing tricky faces. What do I mean by "tricky"? Well, when you e.g. only see a small part of a face and/or the face is in an uncommon angle.
Time for a little experiment
I went over all images and wrote down how many faces I thought I've detected. I would use this number to calculate a vendor's sucess rate for an image and see if it was able to detect as many faces as I did.
However, setting the expected number of faces detected solely by me seemed a bit too biased to me. I needed more opinions.
This is when I kindly asked three coworkers to go through my images and tell me how many faces they would detect.
The only task I gave them was "Tell me how many faces, and not heads, you're able to detect". I didn't define any rules, I wanted to give them any imaginable freedom for doing this task.
What is a face?
When I ran through the images detecting faces, I just counted every face from which at least around a quarter was visible. Interestingly my coworkers came up with slightly different definitions of a face.
- Coworker 1: I've also counted faces which I mostly wasn't able to see. But I did see the body, so my mind told me that there is a face
- Coworker 2: If I was able to see the eyes, nose and mouth, I've counted it as a face
- Coworker 3: I've only counted faces which I would be able to recognize in another image again
Example image #267885

Comparing the results
Now that we have the dataset and the code set up, let’s process all images by all competitors and compare the results.
My FaceDetectionClient class also comes with a handy CSV export which provides some analytical data.
This is the first impression I've received:
| Amazon | IBM | Microsoft | ||
|---|---|---|---|---|
| Total faces detected | 99 / 188 (52.66 %) |
76 / 188 (40.43 %) |
74 / 188 (39.36 %) |
33 / 188 (17.55 %) |
| Total processing time (ms) | 57007 | 43977 | 72004 | 40417 |
| Average processing time (ms) | 1727 | 1333 | 2182 | 1225 |
Very low success rates?
Amazon was able to detect 52.66 % of the faces defined, Google 40.43 %, IBM 39.36 % and Microsoft even just 17.55 %.
How come the low success rates? Well, first off, I do have lots of tricky images in my dataset.
And secondly, we should not forget that we, as humans, do have a couple of million years worth of evolutionary context to help understand what something is.
While many people believe that we've mastered face detection in tech already, there's still room for improvement!
The need for speed
While Amazon was able to detect the most faces, Google’s and Microsoft’s processing times were clearly faster than the other ones. However, in average they still need longer than one second to process one image from our dataset.
Sending the image data from our computer/server to another server surely scratches on performance.
Note: We’ll find out in the next part of the series if (local) open source libraries could do the same job faster.
Groups of people with (relatively) small faces
After analyzing the images, Amazon seems to be quite good at detecting faces in groups of people and where the face is (relatively) small.
A small excerpt
| Image # | Amazon (faces detected) |
Google (faces detected) |
IBM (faces detected) |
Microsoft (faces detected) |
|---|---|---|---|---|
| 109919 | 15 | 10 | 8 | 8 |
| 34692 | 10 | 8 | 6 | 8 |
| 889545 | 10 | 4 | none | none |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Example image #889545 by Amazon
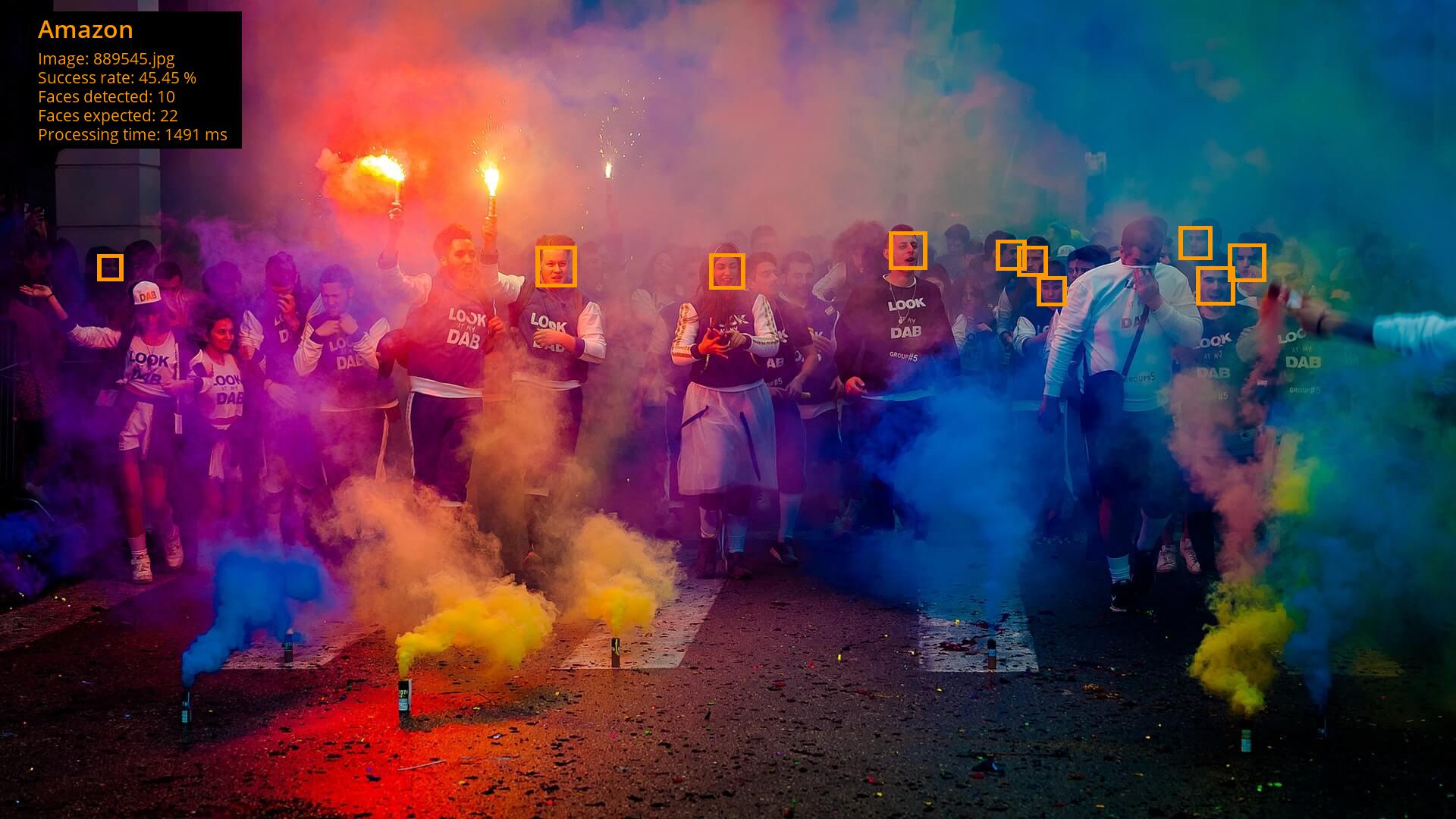
Different angles, uncomplete faces
So, does it mean that IBM is simply less good than their competitors? Not at all. While Amazon might be good in detecting small faces in group photos, IBM has another strength:
Difficult images.
What do I mean with that? Well, images with faces where the head is in an uncommon angle or maybe not shown completely.
Here are three examples from our dataset from which IBM was the sole vendor to detect the face.
Example image #356147 by IBM

Example image #403448 by IBM

Example image #761963 by IBM

Bounding boxes
Yes, also the resulting bounding boxes are different.
Amazon, IBM and Microsoft are here very similar and return the bounding boxes of a person’s face.
Google is slightly different and focuses not on someone’s face but on the complete head (which makes more sense to me?).
Example image #933964 by Google

Example image #34692 by Microsoft

What is your opinion on this? Should an API return the bounding boxes to the person's face or to the person's head?
False positives
Even though our dataset was quite small (33 images), it contains two images on which face detection failed for some vendors.
Example image #167637 by Amazon

In this (nice) picture of a band, Amazon and Google both didn’t detect the face of the front man but of his tattoo(!) instead. Microsoft didn't detect any face at all.
Only IBM succeeded and correctly detected the front man’s face (and not his tattoo).
Well played IBM!
Example image #948199 by Google

In this image Google somehow detected two faces in the same region. Or the network sees something which is invisible to us. Which is even more scary.
Wait, there is more!
You can find the complete dataset with 33 source images, 4x 33 processed images and the metadata CSV export on GitHub.
Not only that, if you clone the repository and enter your API keys, you can even process your own dataset!
At last but not least, if you know of any other face detection API, feel free to send me a pull request to include it to the repository!
How come the different results?
As stated in the beginning of this blog post, none of the vendors completely reveal how they implemented face detection.
Let’s pretend for a second that they use the same algorithms and network configuration - they could still end up with different results depending on the training data they used to train their neural network.
Also there might be some wrappers around the neural networks. Maybe IBM simply rotates the image 3 times and processes it 4 times in total to also find uncommon face angles?
We may never find out.
A last note
Please keep in mind that I only focused on face detection. It’s not to confuse with face recognition (which can tell if a certain face belongs to a certain person) and also I didn’t dive deeper into other features the API’s may provide to you.
Amazon for example, tells you if someone is smiling, has a beard or their eyes open/closed. Google can tell you the likeliness if someone is surprised or wearing a headwear. IBM tries to provide you an approximately age range of a person including its likely gender. And Microsoft could tell you if a person is wearing any makeup.
The above points are only a few examples of what this vendors can offer to you. If you need more than just basic face detection, I highly recommend you to read and test their specs according to your purpose.
Conclusion
So, which vendor is now the best? There is really no right answer to this. Every vendor has its strengths and weaknesses. But for “common” images, Amazon, Google and IBM should do a pretty good job.
Microsoft didn't really convince me though. With 33 out of 188 faces detected, they had the lowest success rate of all four vendors.
Example image #1181562 by Google

Example image #1181562 by Microsoft

What about OpenCV and other open source alternatives?
This question will be answered in the next part of this series. Feel free to subscribe to our data science RSS feed to receive related updates in the future and thank you so much for reading!